


简单介绍
技术创新永无止境,人工智能尤其如此。在过去的几年里,我们看到深度学习模型作为人工智能的先行者再次流行起来。这些由密集互连的节点层组成的模型也称为神经网络,这些节点相互传递信息,大致上模仿了人类大脑的构造。在 2010 年代初期,最先进的模型拥有数百万个参数,用于特定情绪分析和分类的高度监督模型。当今最先进的型号,例如 DreamStudio、GPT-3、DALL-E 2 和 Imagen 已经接近一万亿个参数,并且正在完成与人类工作相媲美的复杂甚至创造性的任务。以这篇文章的标题图片或摘要为例,都是由人工智能制造的。我们才刚刚开始看到这些模型的社会和文化影响,因为它们塑造了我们学习新事物、相互互动和创造性地表达自己的方式。
然而,今天许多技术诀窍、关键数据集和训练大型神经网络的计算能力都是封闭的,并由谷歌和 Meta 等「科技巨头」公司把关。虽然 GPT-NeoX、DALLE-mega 和 BLOOM 等开源模型的复制品由 StabilityAI、EleutherAI 和 HuggingFace 等组织率先推出,但 Web3 有望进一步为开源人工智能提供更多动力。
「人工智能的 Web3 基础设施层可以引入开源开发、社区所有权和治理以及普及的元素,从而在开发这些新技术时创造新的模型和效率。」
此外,Web3 的许多关键用例将通过采用人工智能技术得到加强。从生成艺术 NFT 到 元宇宙景观,AI 将在 Web3 中找到许多用例。开源 AI 符合 Web3 的开放、去中心化和民主化的精神,代表了科技巨头提供的 AI 的替代方案,而科技巨头不可能很快变得开放。(科技巨头 Big Tech,是对信息技术 IT 行业最大、最具主导地位的公司之合称,尤其指美国的亚马逊公司、苹果公司、Google (Alphabet)、Meta 及微软。这些公司不只在美国,在世界的信息技术产业也占有龙头地位。)
基础模型
基础模型是在大量数据集上训练的神经网络,用于执行通常需要智能人类行为的任务。这些模型已经创造了一些令人印象深刻的结果。
OpenAI 的 GPT-3、Google 的 LaMDA 和 Nvidia 的 Megatron-Turing NLG 等语言模型具有理解和产生自然语言、总结和合成文本,甚至编写计算机代码的能力。
DALLE-2 是 OpenAI 的文本到图像扩散模型,可以从书面文本中生成独特的图像。谷歌的人工智能部门 DeepMind 已经产生了竞争模型,包括 PaLM,一个 540B 参数的语言模型,以及 Imagen,它自己的图像生成模型,在 DrawBench 和 COCO FID 基准上优于 DALLE-2。Imagen 不仅产生的效果更逼真还具有拼写能力。
谷歌的 AlphaGo(是于 2014 年开始由英国伦敦 Google DeepMind 开发的人工智能围棋软件) 等强化学习模型已经击败了人类围棋世界冠军,同时发现了在该游戏三千年历史中从未出现过的新策略和下棋技巧。
Big Tech 处于创新的最前沿,建立复杂基础模型的竞赛已经开始。尽管该领域的进步令人兴奋,但有一个关键主题值得我们关注。
在过去的十年中,随着人工智能模型变得越来越复杂,它们也越来越不向公众开放。
科技巨头正在大力投资于生产此类模型并将数据和代码作为专有技术保留下来,同时通过其模型训练和计算的规模经济优势来保持其竞争护城河。
对于任何第三方来说,生成基础模型都是一个资源密集型过程,具有三个主要瓶颈:数据、计算和货币化。
在这个方向,我们看到了 Web3 在解决其中一些问题的早期进展。
数据集生产可以通过 Web3 所有权进行汇总
标记数据集对于构建有效模型至关重要。人工智能系统通过归纳数据集内的示例进行学习,并随着时间的推移不断改进训练。然而,高质量的数据集汇编和标记需要专门的知识和处理,以及计算资源。专门的内部数据团队来处理大型专有数据集和 IP 系统,以训练他们的模型,并且几乎没有动力开放对其数据的生产或分发的访问。
已经有一些社区正在向全球研究者社区开放和访问模型训练。
- Common Crawl,一个十年互联网数据的公共存储库,可用于一般培训。(尽管研究表明,更精确、更精简的数据集可以提高模型的一般跨领域知识和下游概括能力。)
- LAION 是一个非营利组织,旨在向公众提供大规模机器学习模型和数据集,并发布了 LAION5B,这是一个 58.5 亿 经过 CLIP 过滤的图像 – 文本对数据集,一经发布就成为世界上最大的公开访问的图像 – 文本数据集。
- EleutherAI 是一个分散的集体,发布了最大的开源文本数据集之一,称为 The Pile。The Pile 是一个 825.18 GiB 的英语语言数据集,用于使用 22 个不同数据源的语言建模。
目前,这些社区是以非正式的方式组织起来的,并大量依靠广大志愿者的贡献。为了激励社区贡献,代币激励可以作为一种机制来创建开源的数据集。 代币可以根据贡献来发放,比如标记一个大型的文本 – 图像数据集;并且 DAO 的存在可以验证此类激励声明。最终,大型模型可以从一个公共池中发行代币,并且基于所述模型构建的产品的下游收入可以累积到代币价值中。这样一来,数据集贡献者可以通过他们的代币持有大型模型的股份,而研究人员将能够在开放中对构建的资源进行货币化。
编译构建良好的开源数据集对于扩大大型模型的研究可访问性和提高模型性能至关重要。可以通过增加不同类型图像的大小和过滤器来扩展文本 – 图像数据集,以获得更精细的结果。非英语数据集将需要用于训练非英语人群可以使用的自然语言模型。逐渐地,我们可以使用 Web3 更快、更公开地实现这些结果。
随着时间的推移,计算将转移到去中心化网络
训练大规模神经网络所需的计算是基础模型中最大的瓶颈之一。在过去十年中,训练 AI 模型的计算需求每 3、4 个月翻一番。在此期间,人工智能模型已经从图像识别到使用强化学习算法,再到在战略游戏中击败人类冠军,以及利用转化器训练语言模型。例如,OpenAI 的 GPT-3 有 1750 亿个参数,训练时间为 3640 petaFLOPS-day(petaflop/s-day(pfs-day)包括一天里每秒执行 1015 个神经网络操作,或者总共大约 1020 个操作 )。在世界上最快的超级计算机上,这需要两周时间,而标准笔记本电脑需要一千年以上的时间来计算。随着模型规模的不断增长,计算仍然是该领域发展的瓶颈。
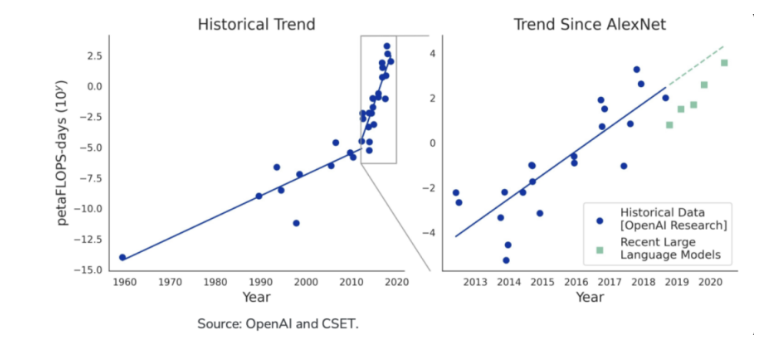
AI 超级计算机需要经过优化的特定硬件,以执行训练神经网络所需的数学运算,例如图形处理单元 (GPU) 或专用集成电路 (ASIC)。如今,针对此类计算优化的大多数硬件都由少数寡头云服务提供商控制,例如 Google Cloud、Amazon Web Services、Microsoft Azure 和 IBM Cloud。
这是我们看到通过公共的、开放的网络进行去中心化的计算分配的下一个主要交叉点。去中心化治理可用于资助和分配资源以培训社区驱动的项目。此外,去中心化的市场模型可以跨地域公开访问,这样任何研究人员都可以访问计算资源。想象一个通过发行代币来众筹模型训练的赏金系统。成功的众筹将为其模型获得优先计算权,并在需求量大的地方推动创新。例如,如果 DAO 有很大的需求,要制作一个西班牙语或印地语的 GPT 模型(Generative Pre-trained Transformer(GPT)系列是由 OpenAI 提出的非常强大的预训练语言模型,这一系列的模型可以在非常复杂的 NLP 任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,Q&A 等,而完成这些任务并不需要有监督学习进行模型微调。)以服务于更大范围的人口,那么研究就可以集中在这个领域。
像 GenSyn 这样的公司已经在努力推出协议,以激励和协调替代、经济高效和基于云的硬件访问,以进行深度学习计算。随着时间的推移,在我们共同探索人工智能的前沿,使用 Web3 基础设施构建的共享、分散的全球计算网络将变得更具成本效益,以扩展和更好地为我们服务。
开放获取和产品协调
数据集和计算将使这篇论文变得可能:开源人工智能模型。在过去的几年里,大型模型变得越来越私人化,因为制作这些模型所需的资源投资已经推动项目成为闭源的了。
以 OpenAI 为例。OpenAI 成立于 2015 年,是一家非营利性研究实验室,其使命是为全人类的利益生产通用人工智能,这与当时的人工智能领导者谷歌和 Facebook 形成鲜明对比。随着时间的推移,激烈的竞争和资金压力逐渐侵蚀了透明度和开源代码的理想,因为 OpenAI 转向营利性模式并与微软签署了 10 亿美元的大规模商业协议。此外,最近的争议围绕着他们的文本到图像模型 DALLE-2,因为它的普遍审查制度. (例如,DALLE-2 禁止使用「枪」、「执行」、「攻击」、「乌克兰」等词语还有名人图像;这种粗暴的审查制度阻止了诸如「勒布朗詹姆斯攻击篮筐」或「程序员执行代码行’ 的提示)访问这些模型的私人测试版对西方用户具有隐含的地理偏见,这导致切断全球大部分人口与这些模型的交互和通知。
这不是人工智能应该传播的方式:由几家大型科技公司看守、监管和保护。与区块链的情况一样,新技术应该尽可能公平地应用,这样它的好处就不会集中在少数可以使用的人身上。人工智能的复合进展应在不同行业、地域和社区之间公开利用,共同发现最具吸引力的使用案例,并就人工智能的公平使用达成共识。保持基础模型的开源可以确保防止审查,并在公众视野下仔细监测偏见。
借助通用基础模型的代币模型,将有可能聚集更多的贡献者,他们可以在发布代码开源的同时将其工作货币化。像 OpenAI 这样以开源论文为基础建立的项目不得不转向一个独立的资助公司,以竞争人才和资源。Web3 允许开源项目在经济上同样有利可图,并进一步与由 Big Tech 私有投资领导的项目竞争。此外,在开源模型之上构建产品的创新者可以放心地构建,因为底层人工智能是透明的。其下游效应将是新型人工智能用例的快速采用和上市。在 Web3 领域,这包括对智能合约漏洞进行预测分析的安全应用程序,可用于铸造 NFT 和创建元界景观的图像生成器,可存在于链上以保留个人所有权的数字 AI 个性等等。
结论
人工智能是当今发展最快的技术之一,将对我们整个社会产生巨大影响。今天,该领域由 Big Tech 主导,因为对人才、数据和计算的金融投资为开源开发创造了重要的护城河。Web3 整合到 AI 的基础设施层将是关键步骤,确保人工智能系统以公平、开放和可访问的方式构建。我们已经看到开放模型在 Twitter 和 HuggingFace 等开放空间中采取快速、公共创新的位置,而加密货币可以推动这些努力超前发展。
以下是 CoinFund 投资团队在 AI 和 crypto 的交叉点上所寻找的项目:
- 以开放式人工智能为核心的团队
- 管理公共资源(如数据和计算)以帮助构建 AI 模型的社区
- 利用人工智能将创造力、安全性和创新带入主流应用的产品
(声明:请读者严格遵守所在地法律法规,本文不代表任何投资建议)
