
铁震:前 Google 工程师,之前 TensorFlow 团队的。去年十一月加入 Hugging Face,见证了 LLM AIGC 的变化,今天有幸受到 CFG 的邀请,想给大家看一下我在 Hugging Face 上看到有趣好玩的模型,希望给大家启发。我不是做模型研究的,我会用通俗易懂的语言,用实战的思路帮助大家理解。
第一章: Hugging Face 的历史
Hugging Face 最早是做 Chatbot 的,做的比较,当时大模型还没有出现,和 ChatGPT 没法比。后来 Google 发布了 Bird, Google 当时做了 TensorFlow, 不过社区已经逐步转向 Pytorch. 所以我们就做了 Pytorch 版的 Bird 副线,把 weights 经过一些办法转化 Pytorch 这种方式,并不是我们重新去训练, 结合这个就慢慢形成了 Transformers。Transformer 是一个模型结构,transformers 是我们这个库,涵盖了所有常用的用到 transformer 结构的这些模型。我们说开发者,researcher 可以很容易把新的模型加上来,用户也可以用同样一个接口,用起来有不同种模型,不仅仅是 NLP(自然语言处理), CV (计算机视觉)很多领域都在用基于 Transformer 这种架构模型。文生图起来之后呢,我们又对扩散模型做了一个类似的库,叫做 diffusers,把扩散模型都收录进来。这是我们库的主要两个产品;另外做的一个产品就是 Hugging Face Hub。Hugging face.co。我分享下屏幕。
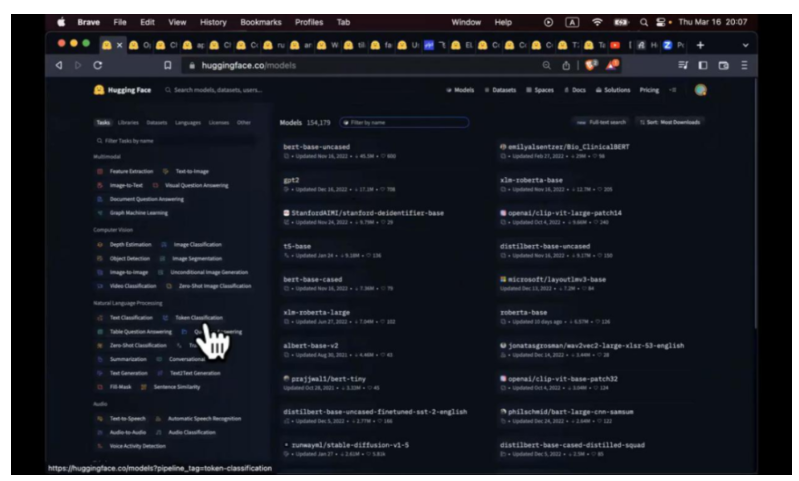

和 Github 比较像,有几个板块。
1)模型:有 models, 有各种各样的模型,我们现在已经有 15 万的模型了。大家如果想学习 NLP 模型,或者想玩什么,就可以在左边 filter 找一下。这里是按照 task 分类的。我个人的理解,NLP 现在用不太上,现在 GPT 太强大了,把整个 NLP 领域都吃掉了。但是 audio (音频), computer vision (计算机视觉), multimodal (多模型)这块,还是有些不错的模型。Models, 自己训练了什么模型都可以上传,他和 Github 最大的不同,上传模型后,我们可以帮你存大文件。举个例子,这个模型 GPT-2, OpenAI 一个很早的模型,随便一个文件 tflite,有 400 多兆(MB)。Pytorch 这个文件是 500 多兆,Github 无法储存这么大的文件,我们提供的服务包括大文件的存储和大文件的 CDN 服务。模型界面右边有 hosted inference API。你这个模型传上来之后,他会去猜这个模型正在干嘛。看到 GPT-2, 他会知道可能是一个文本生成模型,text generation,会帮你设置 weject…你可以在这与你的模型进行交互。这里的例子就是我的名字是什么,后面的蓝色字体就是生成出来。
2)Datasets: 训练模型的时候用了 datasets, 或者准备了一些,这里比较有意思的 filter 就是 size。我们这里存储最大的模型是什么样的,最大的是 poloclub/diffusiondb,大小是几个 T(size categories 大于 1T),每个文件都是几百兆,我们提供免费服务。最后一个有意思的模型是 Spaces。最后一个也是我觉得最有意思的是 Spaces,其实就是可以跑的 Github 应用。Github 把代码开放出来之后,具体怎么跑,装什么 dependency 才可以跑,不是特别确定。Spaces 可免费提供 easy to use instance。 亚马逊的虚拟机,你在上面可以直接跑起来。你也可以挂一些 GPU,把大的模型跑起来试下功能。这个 OpenChatKit 是最近比较火的,不过这个机器人有点傻,我之后会给大家介绍更多更强大的机器人。这个机器人主要目的是提供 feedback,你可以给他打分,回复好,不好。这个数据会被汇总,以后再训练 openchatkit 的时候,Open Kit System 就会记录下来。有点像 reinforcement learning from human feedback,把这个评分,下次降低他的有限级别,等等。这个就是 Space 的介绍。
Chloe: 如果不停喂不好数据,会不会影响模型?怎么解决?
铁震:肯定的。微软推出小冰的时候就被大家玩坏了。喂了一些奇奇怪怪的东西,把小冰心智扰乱了,都会遇到这样的问题。可以做一些数据级的审核,包括 feedback,哪些是可以记录到长期记忆中,哪些是食用下就结束了,都需要进行仔细的判断。
另外给大家介绍一个比较有意思的,如果大家想来 hugging face 玩,注意下 Trending 这个 page。目前很多开源模型都会直接放在 hugging face 上面,可以看到哪些模型比较火,比如我们看模型类别,清华的 chatglm-6b 就比较火,1 万多的下载,200 多的点赞,这里下载量为两周下载量,而不是 Github 上所有的下载量,所以看上去数值比较小。另外 ControlNet, Stable Diffusion, OrangeMixs, anything 我之后会介绍, 非常火的文生图模型。Spaces 是非常有意思的,发布模型后,有很多人会写 UI 界面,我们刚才也看了 OpenChatKit。
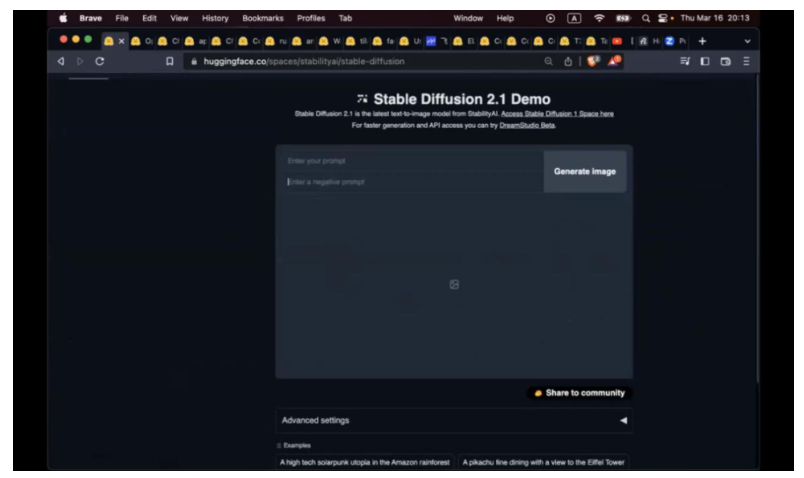
这个 Spaces 大家会看到有前端,有后端,我和他可能还会有一些交互。比如我可以让他生成图片。这个写起来会不会很费力?我输入 A high tech solarpunk utopia in the Amazon rainforest (low quality) 在亚马逊热带雨林高科技太阳朋克乌多邦(不会)。比如我们看 Stable Diffusion 这个代码, gitattributes,README 这些都不用看。看 app.py,读一下他的代码,其实非常简单。下面是一堆 html,去 render 这个 page。核心的代码就是 infer 函数(15 行)。一旦用户点了 bottom 之后,然后我们就做点事情,就把 image 生成出来。Return image, 然后就在 UI 上展示。这个就是用 gradio 来做 (gradio.app),如果大家感兴趣可以了解下。核心思想就是说用不了几行代码,就可以写几行前后端分离的页面出来,大大提高了 AI app 的生产力。这就是 Hugging Face 的简单介绍。
第二章 Hugging Face 上有趣的 Space
Spaces 我自己有 awesome Hugging Face Spaces 的 list, 现在已经不够 awesome 了,chatGPT 真的是太牛了。4 出来之后,很多 spaces 距离商业化的产品还差很多,但是还是有些大家会感兴趣。比如说 YOLO, 如果是上一波做 CV 的话,YOLO 是非常常见的做 detection 的模型。核心的思想就是可以把这个里面的东西找出来,比如说让城市摄像头去数一数街道上有多少辆车。可以跑一个 YOLO 模型,帮你找 Bounding Box(候选框), 帮你把所有的车找出来。这个作者写了一个 Space, 很直观的看出来 YOLOv8 和 v7 或者其他版本有什么不一样的地方。对于文生图领域,可能更是这样。以前可能看下准确率就够了,就能知道这个模型是好是坏,现在对于很多模型来讲,你需要去试一下,看看和你的手感是否比较配合,或者说在一些使用场景上是否能够满足你的需求。这个结果就跑出来了,因为用了 CPU,所以跑起来比较慢,不过效果还是不错的。
王翼:咱们用浏览器的计算资源跑吗?
铁震:不是,这个是完全后台跑的。如果你创建了一个 space 我们就在后台免费给你 instance。我们免费给你一个 2 核的 CPU, 16GB 内存,然后其他的版本要升级收费。这个是 Large Language Model 的 API,你可以调用不同的 LLMs,我就给大家展示几个我认为最 impressive 的 demo。川虎 ChatGPT 非常有意思。我们知道 ChatGPT 有个 UI 界面,同时也提供 API,可以用 API 与他进行交互。很多人说,我对他这个默认的 UI 界面不是很满意,是不是可以自己写一个完全用 API 实现的 UI 界面的功能。我可以写一个 flatter 的 app, 能够在我手机,电脑上跑。川虎 ChatGPT 就是这样一个实现,完全用 Public API 实现了一个 UI 界面的功能。比如说跑程序的时候大家会看到 Queue:1/1 13.5/14.0s 后面的是预估的时间。Queue 表示你前面还有几个人,1/1 表示你前面还有 1 个人,等前面的人跑完了就轮到你。因为有人排队,所以读取超时。这时候可以 duplicate this space,相当于你为这个 Space 创建一个副本,完全用你自己的资源去跑。什么意思呢。比如说这个是 2 核,16GB 的虚拟机,你 Duplicate 之后呢, 有了自己的虚拟机,你自己用,当然你也可以改为 public 去和别人分享。我这里已经创建好了,可以给大家找一下。上面写 Duplicate from。我就可以和他聊天了。我觉得这个东西最大的价值,如果对于 UI 界面不满,想设计一些比较好的 UI 界面,包括把一些比较好的 prompt.提示当作 template,用这个界面就可以达到这个效果。比如说你可以去看他的代码。这个 Key 我今天可能流量报表,我是 18 美金,免费送的 Key。代码部分,你可以看这个代码做修改,比如说你需要一个创建 Template 功能,你改下代码就可以实现这个功能,这就是开源软件最大的魅力所在。你可以根据需求定制化交互界面和交互方式。比如 word 有个需求,word 没有满足你,你希望做个改动,非常困难的,但是在开源世界,尤其是这种比较轻量级的 app,你可以随意去发挥创造力,做很多很多事情。
王翼:我能不能理解你的这个事情很像 wordpress, 域名和服务器这个事情。Hugging face.co 帮助你管好,你可以做增量定制。
铁震:可以这么理解,不过他比 word presss 功能强大很多。定制化能力还是很强的。你可以用我刚才说的 Gradio,甚至可以直接上传一个 Docker profile 上来,直接在虚拟机上执行,所以扩展性还是蛮好的。
第三章:AIGC 和 Demos
AIGC 和空耳这种现象非常相近,给大家举个例子。当你去听韩语或者印度歌, 第一次听的时候你可能觉得他是噪音,讲什么听不懂,你可能知道他有点韵律,他说什么你不清楚。一旦你看了字幕,这个字幕实际上是有人把他听出来,用中文的,发音非常像的词语描述一下,再去听的时候,你可能觉得这个就是讲的这个歌词,虽然歌词非常无厘头,比如说的我说你别介意不洗澡。一旦你接受了歌词的设定,再去听这首歌的时候,你就会发现他好像唱的就是这个东西,再也不是一个噪声了,而是一个字幕在说的事情。对于 AIGC 讲的是同样的事情。
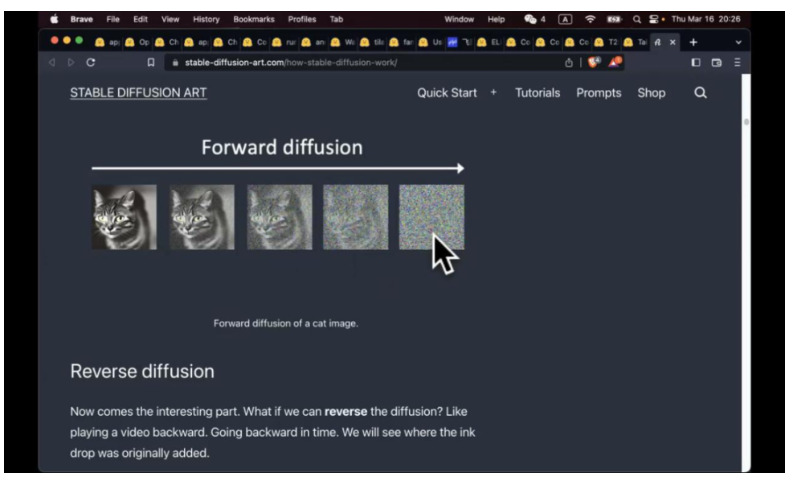
扩散模型是怎么回事呢,实际上一个降噪的过程。我们想象加噪声是什么样的过程。原来是一张图,一点点加噪声,一点点加噪声,慢慢的图是什么我们就看不清了。和我们刚才听歌一样,一开始是非常清晰的声音,经过麦克风录制一次声音就变差一次,经过我把喇叭放出来,经过我电脑麦克风收进去,再到喇叭放出的时候,可能就是噪音了。Diffuison model 做的是反向的过程,需要把噪音里面的信息提取出来,如何提取呢,如果你完全不给他方向,韩语歌你让他听 100 遍,还是听不懂是什么,永远都是在这个状态,让他往左边走的模式就是我给他一个 prompt, control, imbedding,给他额外的信息,让他去空耳,让他感觉我好像看到的是右数第二张图,就会一点点从最右边的图片往左边移动。这里我好像看到一只猫。其实我看了右数第二张图,再看右数第一张图,我是依稀能看到有个猫出来的。走完第一步,就可以走第二部,最后完全还原出猫。认为杂乱无章的图片是一只猫,他就会一点点看出一只猫。至于原来是什么不重要,韩语唱的是什么不重要,我满脑子就是不洗澡。
License:其实做文生图很少关注 license, 做开源软件也很少关注 license,这个领域处于灰色地带,但是在某些地区比如美国,已经有些 lawsuit,已经有些影响。一旦第一个判例法出来,对后面可能有比较大的影响。没有人知道这个东西是什么,发布软件的还是想一下 license。Stable Diffusion 这个 license 还是比较 general。我的这个模型,或者任何我模型的变体(用我模型任何一点东西的变体,微调出来的模型也好,修改过的模型也好,你都不能做 illegal, harmful 或者 discrimination 的事情。举个例子,你没有经过任何人的同意,画了一幅他的肖像画,手画的在我们看来应该不是一个问题。但是如果你未经过任何人同意,用 AIGC 的工具,用 Stable Diffusion 去创作了人像,根据我对 license 的理解,可能就是违反 license 的行为。为什么我觉得比较宽容,因为可以用作 commercial use。 和她做对比,MJ 有个限制,免费的用户只能把生成的图片做个人使用,不能把他做 commercial use。只有成为付费的用户,才能在商业场合用 MJ 给你生成的图片,并且 MJ 这个公司是有权使用你生成的这些图片的。这个和 Stable Diffusion 有比较大的区别。为什么说这个东西还是在灰色地带呢,因为虽然有这个 license,美国的版权法按照他现在这个这个法律,只适用于人创作的作品,AI 创作的作品没有 owner, 没有这个 copyright,后面如何发展我不清楚。这个事情影响越来越大,不仅仅是艺术家会遇到这样的问题,代码生成,chatgpt 都会遇到这样的问题,我能不能用任意的东西去训练,没有版权许可的东西去做训练。训练出的模型,生成的内容究竟归谁所有。这是一个比较大的问题,我没有答案,我只是给大家 FBI warning。用任何一个模型之前,要看一下 license 是怎么样的。
王翼:这个版权 我的理解是训练数据肯定是有版权的,只要把训练数据的版权解决了,有两种解决方式,第一种买断,竟然训练数据归你,那么通过训练数据再创作,再生成仍然归你。第二个就是你只有使用权,你只使用元数据进行训练,那你没有所有权,那你生成的这个东西,你也只有使用权,你没有无限权力商业制作,商业权应该归元数据所有人所有,只不过需要确认,因为这个是间接的。如果找到了途径,比如通过图片对比发现你和他图片某些很相近,他认为这个是属于 training, 而不是 inference,就可以起诉。
铁震:有可能。我不是律师,但是我个人觉得会稍微复杂,不同利益相关的人不一样。首先是最原始的创作者,人类艺术家,然后是数据集创作者,比如 Laion, the Pile (eleuther.ai),把数据收集起来,成为一个数据集的人,还有 Stable Diffusion 这种训练模型的人,拿这些数据集是用有版权的数据,然后把这些模型训练出来的人。训练出来的人,还有做推理的人,比如说我用 Stable Diffusion 做一个推理,实际上借由我版权的相关,也有 Stable Diffusion 相关。甚至说用 AIGC 生成图片之后,我又做了一些改动,或者说别人拿我的图片做些什么。所以这中间蛮长的链条,不是说我只要训练,推理就好。最近有几个官司可以关注下。简单做下展示。
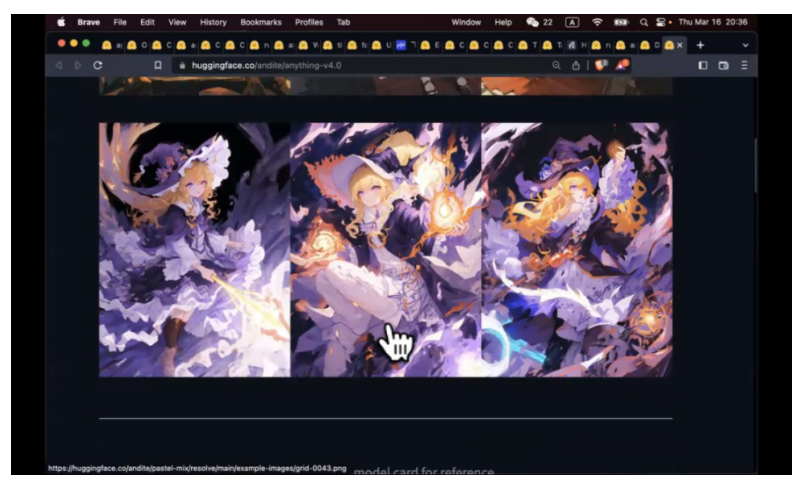
大家知道 Stable Diffusion 有自己的模型,比如说 Stable Diffusion v1-5, 我们用原始模型去生成一些东西,大家可以去对比下效果。再拿比 anything v4 (Fantasy.ai) 微调过的模型去看下效果。Anything v4 有点动漫风格。不同模型,训练集,训练方法,训练权重,都不一样,风格也不一样。

王翼:现在可以通过 prompt 做 animation 吗?固定一个角色,GPTCHAT, 生成这个角色不同的动作,场景,生成 animation 动画,还有一些短电影。
铁震:我觉得这涉及到两个问题,我是否能够生成一个角色,给他照不同的照片。你看这个 anything v4 这个模型,就是同一个人像,进行不同形式的生成。叠加 ControlNet 之后,你就可以给她摆姿势。第二个问题,我是否能让这个图动起来,这三张图中间插无数张图,导致这个系列动起来,这个技术目前还不成熟。针与针之间就会发生不一样的变化。比如说,第一针有手表,第二针没有,第三针背景亮度会有变化。这是目前比较有挑战的。但是也有很多技术攻克这个东西。Stable Diffusion 到目前也就半年时间,说不定再过半年就有另外模型出来。
Frank:To 3D 的 Netflix 也在做。德国的一家公司 Runway 也是。
铁震:我在一些 AIGC 群里,完全分不清是 AI 生成还是真人,专业认识可以用 AIGC 做一些以假乱真的图片,还是非常厉害的。我们 Diffusers Gallery 就有 AIGC 的模型和图。有些模型用 LoRA,过会儿会提到,可以把这个当成工具,相当于一个 LoRA 模型就是一个 concept 或者几个 concept,在自己 AIGC 生成的时候,把这个东西用在 AIGC 生成的图片里。
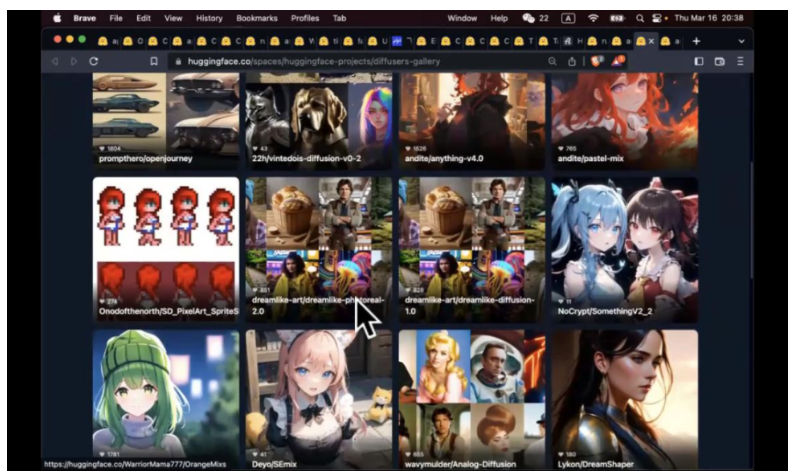
刚才提到,如何让我的模型学到 concept。比如说标准模型有狗的形态,但是你说画一个狗的图片。但是这个狗和你家的狗还是不一样。每条狗都有独特的地方,通过 DreamBooth 技术, 可以让模型学会这一条狗是什么样子,学会之后,我可以在不同场景生成这个狗的照片,我们可以观察到训练集有不同的狗的角度。
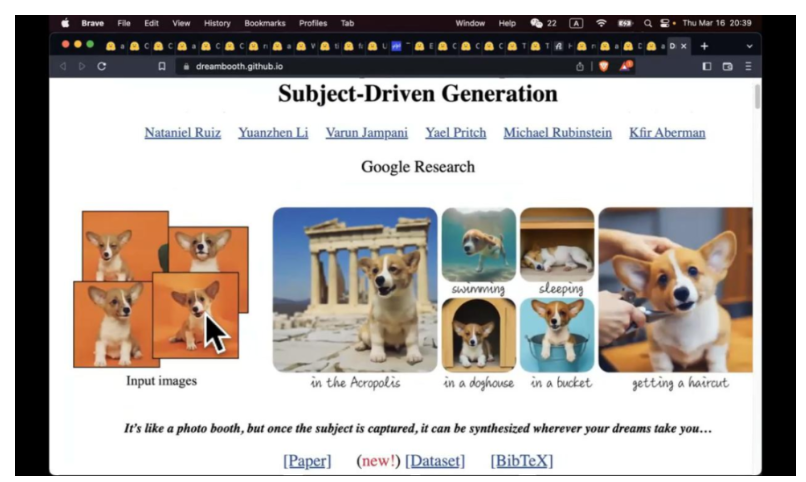
DreamBooth 是一个微调技术,讲究用少数几张照片就可以达到这样的效果。如果你有更多的照片去调参数,可能有更好的效果。如果 3-5 张照片,如果能实现不错的效果,其实就是很好的结果了。这个技术最早是 Google 发明的。但是这不是唯一植入芯的 concept 技术,还有 texing 模式等。我们之前围绕这个技术做了比赛。这里是大家上传的 DreamBooth 模型,获奖的是国潮风,他训练的不是具体的东西,训练的是国朝的风格。
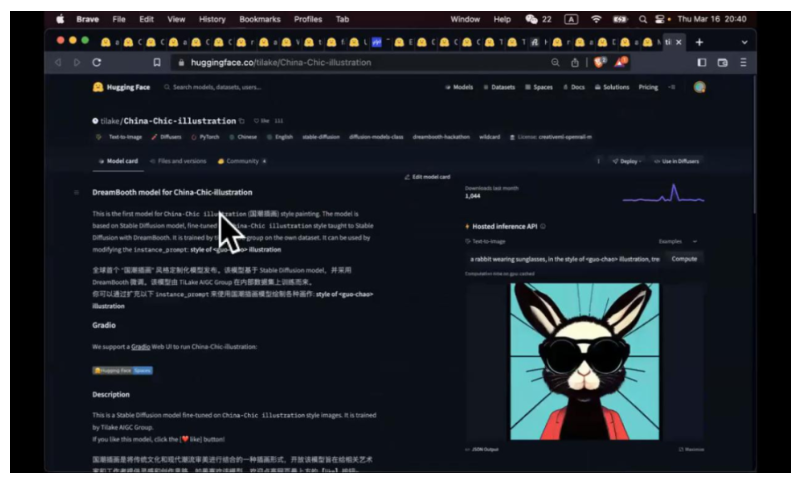
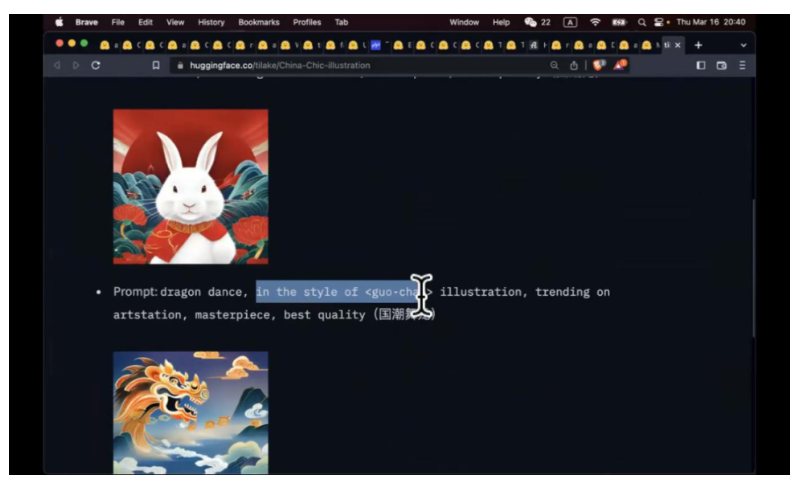
模型训练出来就认识这个咒语:尖括号 guo-chao 尖括号,只要你输入,就意识到你要这个风格。DreamBooth 的问题在于这个模型太大了,训练出来 4-5G。所以后面有个新的技术,两个叠加在一起,就可以把微调的模型变得非常小,比如说 LoRA+DreamBooth。
王翼:Diffusion 模型 1 个 11G 的 GPU 都能够放下,如果再训练的话可能就是 A30,24G 的 A30 就能搞定了吧。
铁震:是的。我觉得 Stable Diffusion 之所以这么火,1)开源 2)巨大的原因,它可以让家用显卡可以跑起来(rather than A100)。DreamBooth+LoRA 叠加起来,模型可以做到 3.3 兆。好处是什么?你可以把你个 LoRA 模型拼在一起,做你想做的效果。时间关系,就不多讲了,欢迎大家参加我们的黑客松。
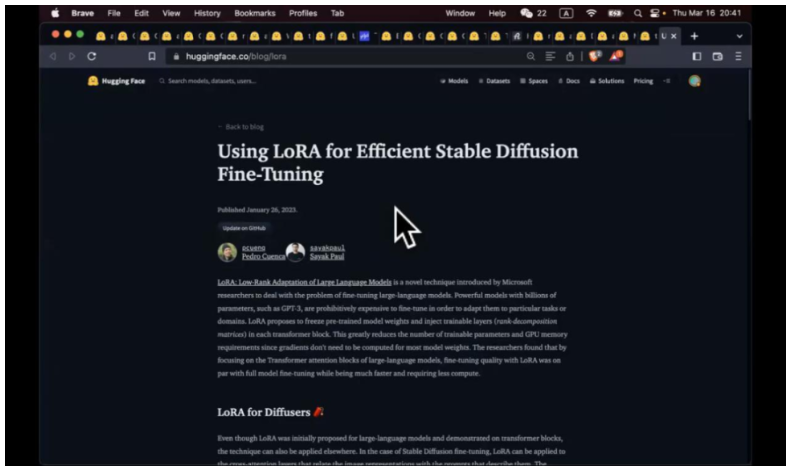
我们和飞桨做了一个比赛,百度飞桨提供算力,提供代码。大家只需要准备几张照片,去参加,选一个 GPU。把照片拖到飞桨的计算中心,跑一下,就可以做出这个模型。
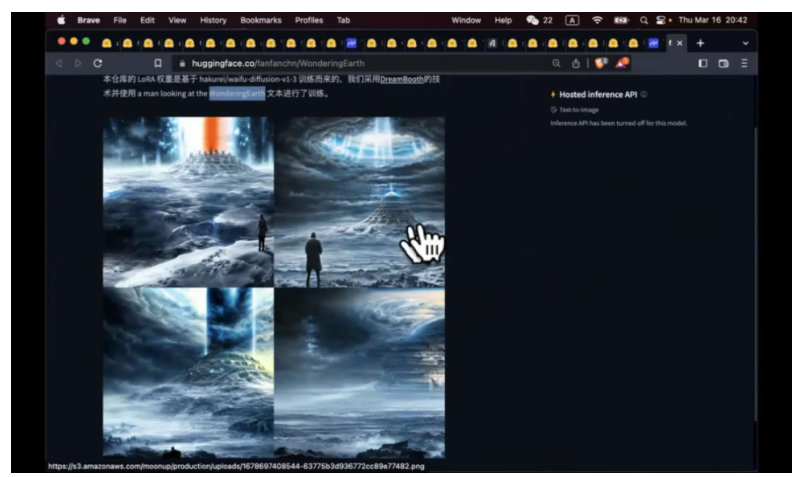
这是一个行星发动机, WonderingEarth。我们看一下这个参赛选手,a man looking at the WonderingEarth。 因为是 LoRA, 可以把不同的 concept 串到一起。假象有个人做了 concept 叫做月球轨道车,prompt a man looking at the WonderingEarth+ 月球轨道车,这里就会出现月球轨道车,你可以把不同的 concept 组合到一起,达到效果,甚至你可以说,国朝风格的行星发动机。当然里面有很多技术细节,大体的思路是这样的。
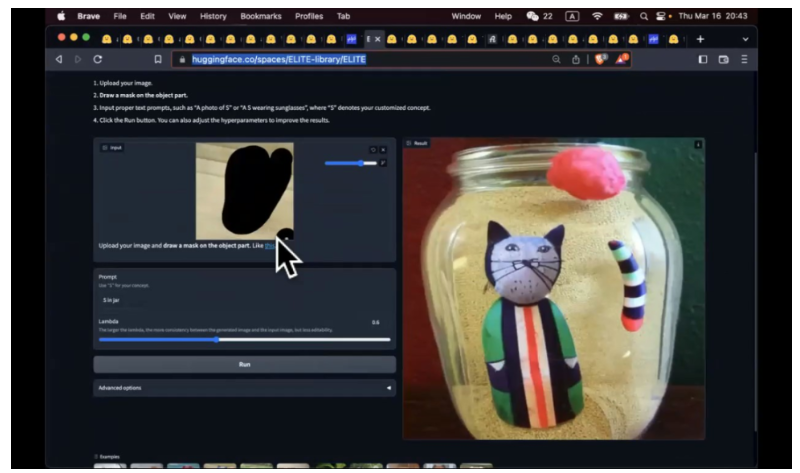
接下来我讲下我个人比较看好的技术,Elite。刚才我们说我让模型学会一个新的概念,我需要有一个训练的过程。对于传统机器学习,fewshot 这个概念,我有没有可能做到 zeroshot。我给你几张照片,你不需要重新微调,微调需要十分钟二十分钟。你能否看到我这张照片就知道我要做什么,直接画出来。举个例子,我选了小猫这张照片,给了他一个 mask,告诉他小猫的这个位置是我想让他在新图片中生成的。这个示例就默认这个概念叫 S, 之前的概念叫做国潮,或者 Wonderingearth,这里叫做 S。我的指令 S 在一个杯子中的(S in jar)照片。我们看到效果还是不错的。如果用 DreamBooth,和 LoRA, 效果会更好。毕竟训练这么久,又有那么多张照片。这个一张照片就可以生成这样的效果。
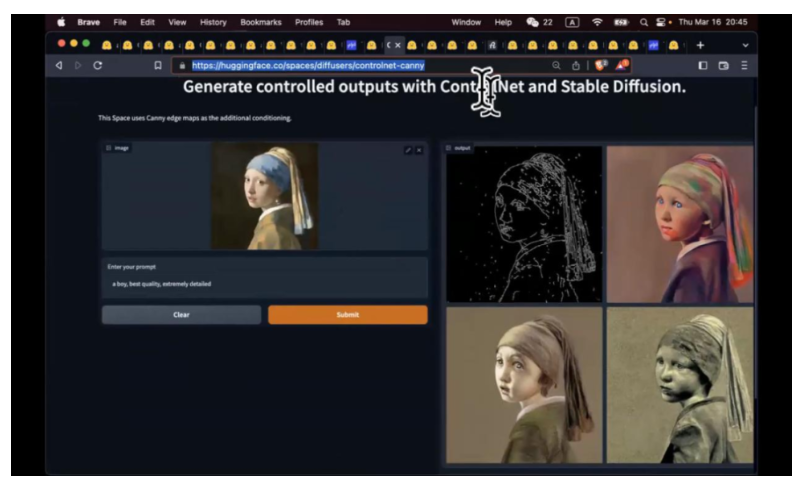
另外一个是 ControlNet, 刚才我们说空耳的时候给你歌词,然后你根据这个歌词去想象歌曲在唱什么。现在我不给你歌词,我给你画,给你其他的 Control, 是不是可以呢,实际上在模型,其实在模型种都是不同的 control,给你算 proseattention。在图像里,你可以给他一个边缘,告诉他,你从这个虚无中看到一个边缘,你能看到什么,然后再额外给你一个 prompt, 然后生成效果。我给他的 Prompt 是一个男孩,有几张照片还是能看出来的,虽然左边是个女孩,但是右边的照片形态上满足了我的要求。他在边缘上也满足了黑白边缘照片的要求。我如果可以画张素描,和他说这个素描画的是什么,他就可以把这个素描填色,修改,光影,都处理好,还可以叠加像 LoRA 这种新技术。把一些 concept 也加进来。
这是另外一种 Control, 刚才我们运用的是边缘,这里是 pose estimation,调用的是另一个 AI 模型去识别,识别骨头关键点,头在哪,手在哪。识别完,再给上 prompt,比如男孩,手没有处理好,头,脚的位置都是不错的。同时给我们生成了四张。这就是 ControlNet, 给他更多 Control, 让他按照你的思路去生成。
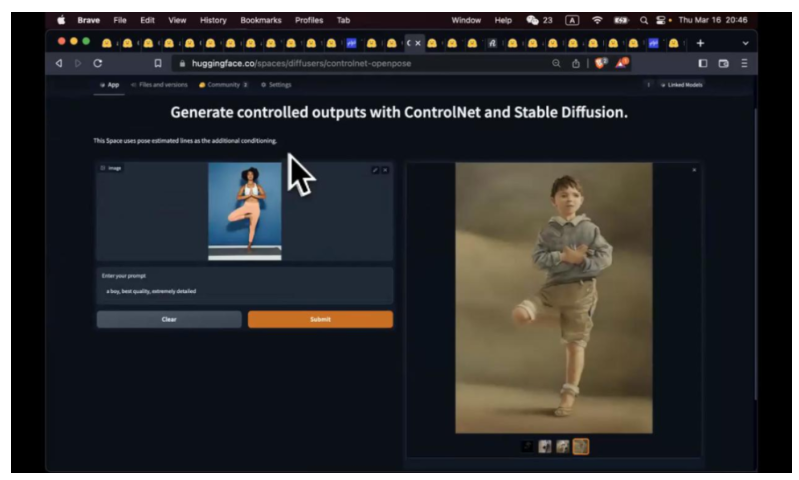
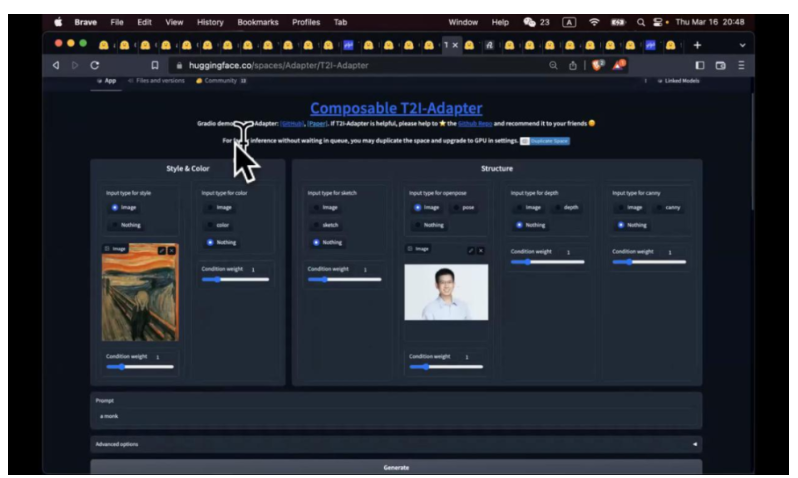
把这个思路往下扩展,可以做更多事情,比如说是否可以把所有 possibilities 全部列出来,我自己去选需要什么。比如说腾讯最近做的 T2-Adapter, 它可以把 Style & Color, Structure, sketch, pose, 深度,边缘全部都用起来。这个例子就是我拿呐喊的图作为 Style, 我要用我的 Pose, 我要画一个和尚。同样手有点诡异。如果我给的全身照,包括手,效果应该会更好。这个有趣的地方你可以把这些东西各种 combination。ControlNet 也可以做,multicontrolNet, 不过 UI 没有这么好,腾讯这个你可以直接选择。
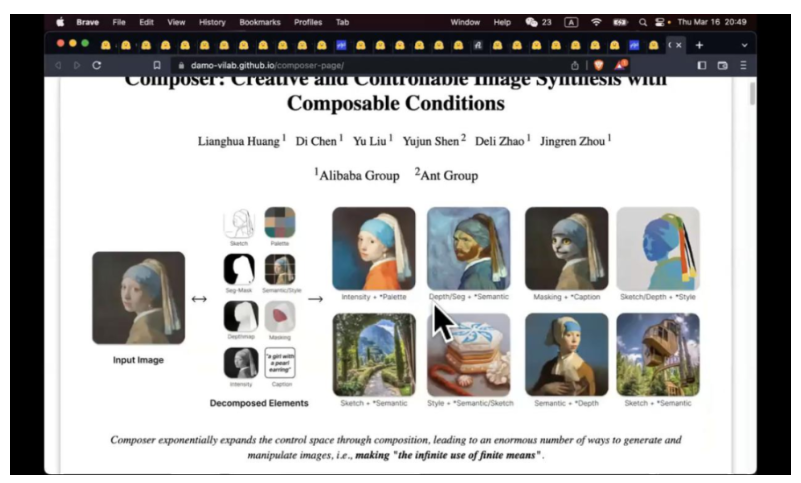
阿里有个新的工作就是 Composer。可以从一张图片中拿到 Sketch,色阶,mask 等等。根据不同组合方式,可以生成不同的图片。目前还没有开源。
接下来介绍一下非模型的,前沿生产力工具。第一个是 Robust Face Restoration 和 upscale 的模式。场景是 Stable diffusion 默认生成 512512 的图,用 upscale 可以生成 20482048 的图。这是 upscaler 的其中一种。可以通过这种方式,看效果如何,如果不错,可以再选择慢一点的 upscale,把图片效果做到更好。
刚才上述介绍的都是单一工具,如果大家以这个谋生或者发展兴趣,需要做 Webui UI 这个开源工具,很多人在 Hugging Face 上去部署。提供了很多功能,这只是阉割版本,有些插件没有安装,但是可以做 text 2 image. 给他 prompt,甚至 negative prompt,很多参数可以选择,随后生成了山水画。局部编辑,指示他在某个位置画飞机,他就可以画飞机,云山雾罩中有个飞机。感觉要从画中飞出来一样。还有 image2image, 大家可以研究。
最后给大家看些声音生成的例子。这里可以用原神人物的风格,生成说的话。唱歌的,帮你生成歌曲。改音高,duration,像我只会改歌词,你有不同的歌曲风格可以去换。现在歌曲的风格,或者说人物的声音,都是需要很多数据去训练,未来或许也会出现类似 LoRA 这种技术,我们可以去选,把不同的风格叠加起来,比如说让邓紫棋唱周杰伦的歌,加上我们自己的歌词。或者未来或出现 zeroshot, 类似于 Elite 风格,我给他一首歌,现场就学了这种风格,分解出不同的维度,根据我的需求选择性拼贴,变成新的歌曲。
Chloe: 之前看的很多 paper 聊了很多训练参数,训练方法,数据集,硬件要求等等。但是你的分享让我感觉 AI 这一波真的是将触达到我们所有的人,每个人都应该学习如何使用这些模型工具。微软 CEO 在一次也说过,如果未来你不会使用这些 AI 工具,就像你现在不会使用智能手机。你把一些比较复杂,学术的东西讲的很深入浅出。对于我们投资人来说,尤其重要的是如何把这些晦涩难懂的东西,去让一些原来对于 AI 没有太多了解,毕竟 AI 行业的门槛比较高,我记得身边所有学习 AI 的都是博士,数学系博士毕业的。现在其实生成式 AI 大大降低了行业门槛,未来掌握了这些核心技巧和功能,所有的人都可以训练自己的模型,自己的数据,我觉得未来的 target 就是触达十亿级别,甚至上百亿用户的新机会。包括现在英国政府也打算斥资数十亿英镑建立超级算力中心,不管是个人,国家,宗教,文化都是需要自己的特质化的模型。铁震作为一线的创业者,解除了大量的创业公司,科技公司,AI 模型,我们发现迭代速度非常快,这几个月 AI 的发展速度超过了过去几年的发展速度。15 年的时候,当时 AllphaGo Progamme 出现的时候,很多业界的人已经有人判定十年后 AI(2024,2025)会迎来巨大的发展机会,这也是我们为会提前布局的原因。
王翼:我现在在 GraphCore 负责算法,我们在做芯片,支撑各种模型的训练。你的这个研究让我了解 Stable Diffusion 以及应用层面的了解。我们之前也跑过 Stable Diffusion model。Hugging face 的工具链,如何控制生成的内容,符合我们的预期,我相信未来会有更多 control,更加自然,通过 prompt,交互式工具。
(声明:请读者严格遵守所在地法律法规,本文不代表任何投资建议)
