
免责声明:每个框架的基准测试设置完全基于我对其各自文档和代码库的解释而确定,可能存在误解,可能导致次优的环境配置、不当的测试数据预处理或参数选择不当,因此,这些因素可能会影响基准测试结果的准确性。
作为常年参加黑客松的老人,我经常纠结于这次比赛我应该选择一个什么题目才更容易获奖?从去年的 ETH Den 开始,我注意到,与零知识(ZK)相关的赛道越来越多,奖金也越发丰厚,那么问题来了:如何在有限的时间内快速开发一个 ZK 相关的应用程序来赢得奖金呢?


这个问题自从去年我参加了由 ABCDE Capital 举办的 ZK 黑客松之后就一直困扰着我。所以我开始学习与之相关的博客或者项目,我想这些肯定有助于我更深入理解 ZK,也是通过一段时间的搜索和学习,我发现了一个不错的 Repo: awesome zkml——她详细的统计了各种学术上或者工业界的成果并一一进行分类。但由于缺乏真正的应用例子和测试结果,所以帮助其实没有那么大。
因此,为了解决这么个问题,我开发了一套 ZKML 基准测试,项目由以太坊基金会 ESP 赞助(FY23-1290)。该基准测试旨在帮助开发人员了解不同框架之间的性能差异。虽然许多框架都提供自己的基准测试集,但由于影响性能的变量众多,直接比较会变得复杂。所以,我的方法侧重于在所有框架中创建统一的条件,以提供实用和直接的比较。
与 EZKL 团队已经发布的基准测试不同的是,我的测试没有侧重于传统机器学习模型,包括线性回归、随机森林分类等,而是专注于神经网络模型重的 DNN 与 CNN。
基准测试概述
本项目进行了为期数月的广泛测试,评估了 4 个领先的 zkML 框架在 6 种不同 DNN 和 CNN 架构上的表现。通过对每个框架在 2500 个 MNIST 数据集上的细致分析,投入了超过 250 个小时进行设置和证明生成,才完成了这样一份文档。其中详尽结果都被细致地记录在 csv 中。
架构
测试网络由深度神经网络(DNN)组成,每个网络都有一个输入层,后面跟着两个或三个完全连接的密集(Dense)层;以及卷积神经网络(CNN),从多维输入开始,采用 Conv2D 和 AvgPooling2D 层来减少空间维度,然后进行扁平化(flatten)处理。每个模型的命名方式源于其各层的大小,由下划线 (‘_’😉 分隔。
例如,名为「784_56_10」的模型表示输入大小为 784 (对应于 MNIST 数据集图像,其为 28×28 像素的灰度图像),后跟一个有 56 个单元的密集层,最后是一个为 10 个不同类别设计的输出层。 CNN 网络 ’28_6_16_10_5′ 表示 28×28 的输入大小,后跟两个大小分别为 6 和 16 的 Conv2D 层。在扁平化层处理来自前一层的输入(256 units)后,CNN 网络输出 10 类推断。最后的 ‘_5’ 指定 Conv2D 层具有 ‘5×5’ 的内核大小。
以下是以 ’28_6_16_10_5′ 模型为例的详细结构:Model: “28_6_16_10_5″_______________________________________________________________________Layer (type) Output Shape Param # =======================================================================input_1 (InputLayer) [(None, 28, 28, 1)] 0 conv2d (Conv2D) (None, 24, 24, 6) 156 re_lu (ReLU) (None, 24, 24, 6) 0 average_pooling2d (AveragePooling2D) (None, 12, 12, 6) 0 conv2d_1 (Conv2D) (None, 8, 8, 16) 2416 re_lu_1 (ReLU) (None, 8, 8, 16) 0 average_pooling2d_1 (AveragePooling2D) (None, 4, 4, 16) 0 flatten (Flatten) (None, 256) 0 dense (Dense) (None, 10) 2570 =======================================================================Total params: 5,142 (20.09 KB)Trainable params: 5,142 (20.09 KB)Non-trainable params: 0 (0.00 Byte)_______________________________________________________________________
主要指标
- 精度损失:衡量每个 zkml 框架生成的推断与原始神经网络生成的预测保持一致的程度。精度损失越低越好。
- 内存使用量:跟踪证明生成过程中的峰值内存消耗,即系统的资源需求。
- 证明时间:每个框架生成证明所需的时间,对于衡量证明系统的效率至关重要。
所选框架
EZKL (Halo 2)
ZKML (Halo 2)
Circomlib-ml (R1CS Groth16)
opML (Fraud Proof)
这些框架是根据 GitHub 受欢迎程度、所使用的证明系统以及对不同 ML 模型格式的支持等标准来选取的。这种多样性确保了在不同 zk 证明系统之间进行广泛的分析。
关于排除 Orion 的说明:由 Gizatech 开发的 Orion 的证明生成过程是在 Giza 平台上执行的。因此,在证明生成期间的内存使用量和时间开销指标与本项目中评估的其他框架不具有直接可比性。为了保持基准测试分析的完整性和可比性,Orion 的基准测试结果被排除在后续部分之外。
关于排除 zkLLVM 的说明:由于 TaceoLabs 最近才发布了 zkLLVM 编译器以及相关教程(发表于 2024 年 3 月 ),因此本项目启动之时,该框架并未被列入我们的基准测试名单。未来我们将进一步研究 zkLLVM 的性能表现。
基准测试设计
我们的基准测试涉及到 MNIST 数据集上的任务,以便在不同复杂性水平下评估框架:
MNIST 数据集:
- 任务简易性:MNIST 数据集包含手写数字,可作为评估 zkML 框架基本能力的基准。
- 框架评估:此任务将衡量每个框架在保持精度和运行效率方面如何处理图像数据。
- 参数变化:各框架将使用该数据集、增加参数、网络层数进行测试,以探索每个 zkml 框架的能力极限。
神经网络设计:
- 为了严格评估每个框架将神经网络转换为 zk 电路的能力,我们设计了六种不同的模型,从 3 层 DNN 到 6 层 CNN,还包括 LeCun 等人于 1998 年提出的最早期的预训练 CNN 模型之一 LeNet。
- 由于 zkML 框架仅支持其中一种标准包(TensorFlow 和 PyTorch),因此统一测试条件并不仅仅在于结构标准化。现有的转换工具(如 ONNX)难以在 TensorFlow 和 PyTorch 之间进行完美转换。因此,我们采用了手动的方法,以符合 TensorFlow 和 PyTorch 计算范式的方式,来确保完美的保留了权重(weights)和偏差(bias)。
- 我们的度量指标完全基于证明生成阶段,因此省略了数据预处理或系统设置步骤。
Here’s a translation of your「Results」section, along with some minor refinements for clarity and a more natural Chinese phrasing:
基准测试结果
在本基准测试中,我们使用了三个主要指标来衡量 zkML 框架的性能:精度损失、内存使用量和证明时间。虽然这些指标具有可量化和可比较性,但要评估一个框架的整体优越性会比较复杂。例如,一个框架可能以牺牲极高的内存使用量和证明时间为代价,来展现出极小的精度损失。
为了解决这一复杂性,我们分别针对相同模型对每个框架的结果进行了归一化处理,并通过雷达图将它们可视化。这种可视化策略提供了对每个框架性能的更直观理解,平衡了这三个可量化的指标。值得注意的是,这种方法意味着以同等权重对待精度损失、内存使用量和证明时间,这在现实场景中可能并不总是准确的。
注意:我们使用了一致的配色方案来表示每个框架在六个测试的神经网络模型上的性能。基准测试结果已经被归一化,每个指标中表现最好的框架在雷达图上得分为 1.0。因此,由精度损失、内存使用量和证明时间的归一化数据形成的三角形面积越大,表示框架的性能越好。
DNN 模型性能
在下面的条形图中,我们展示了每个框架在各个具有不同网络规模的 DNN 模型上的性能结果,涵盖了三个指标。
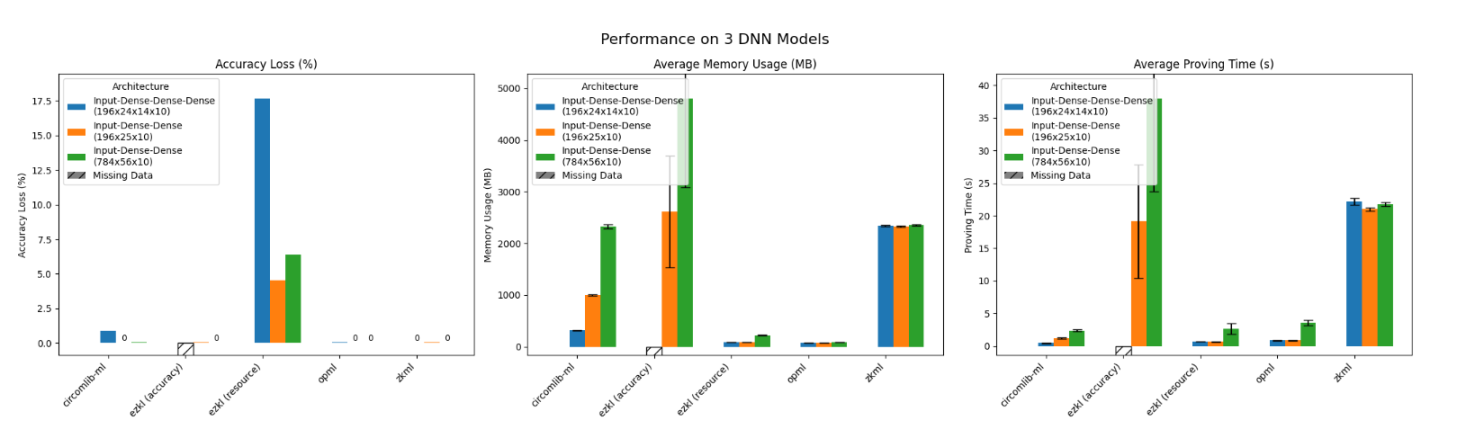
关于 EZKL 的说明: EZKL 提供两种模式 –「accuracy」(精度模式)旨在使用较大的缩放因子(scaling factor)来最小化精度损失,以及「resource」(资源模式),针对资源受限的系统进行优化,在获得可接受的精度损失的同时还能保持良好的效率。 EZKL 的「accuracy」模式在对模型 ‘196_24_14_10’ 进行基准测试时会导致系统崩溃,可能的原因是使用了超过本地服务器 128 GB 内存的限制。我们已将这个测试用例从基准测试中排除,并将在问题解决后将其纳入未来的更新中。
接下来,我们对这些结果进行了归一化,并通过雷达图进行了呈现。显然,Circomlib-ML 与 opml 在基准测试中表现出色,在精度损失、证明时间和内存使用量之间达到了良好的平衡,而这些正是 zkML 应用中生成证明过程的关键因素。
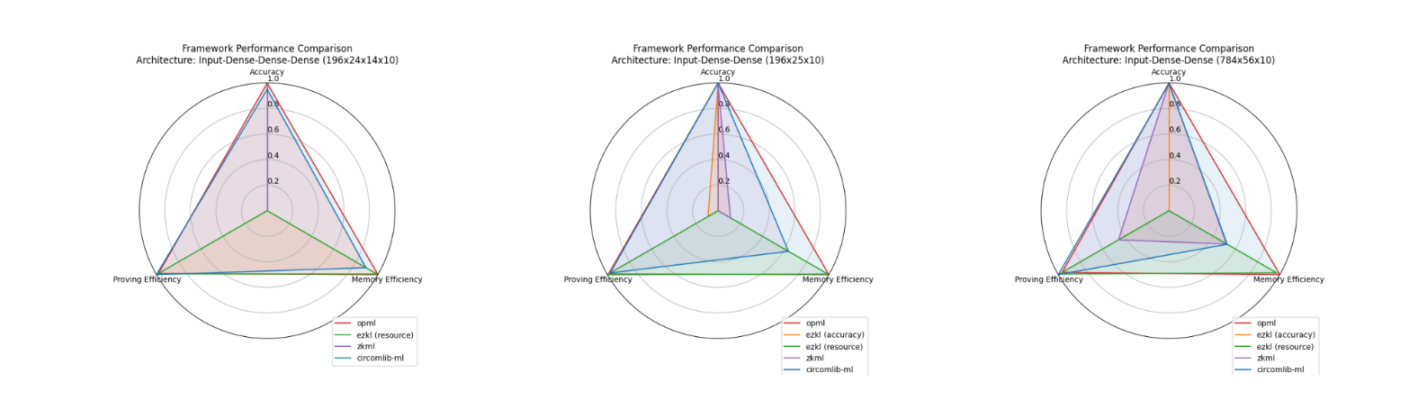
关于 opML 的说明: opML 的机器学习推理方法不同于本次基准测试中的其他 zkML 框架。通常,zkML 过程涉及先计算 ML 推理,然后再为推理结果生成 zk 证明,最终形成可验证的 zkML 证明。相比之下,opML 专注于在虚拟机中执行 ML 推理,并输出代表 VM 状态的 Merkle Root。这个 Merkle Root 承诺了算出的状态,仅当挑战这个承诺时,才会生成欺诈证明(fraud proof)。因此,opML 的基准测试计算成本(内存使用量和证明时间)反映的是在 VM 环境中运行 ML 模型,而不是生成任何证明本身。
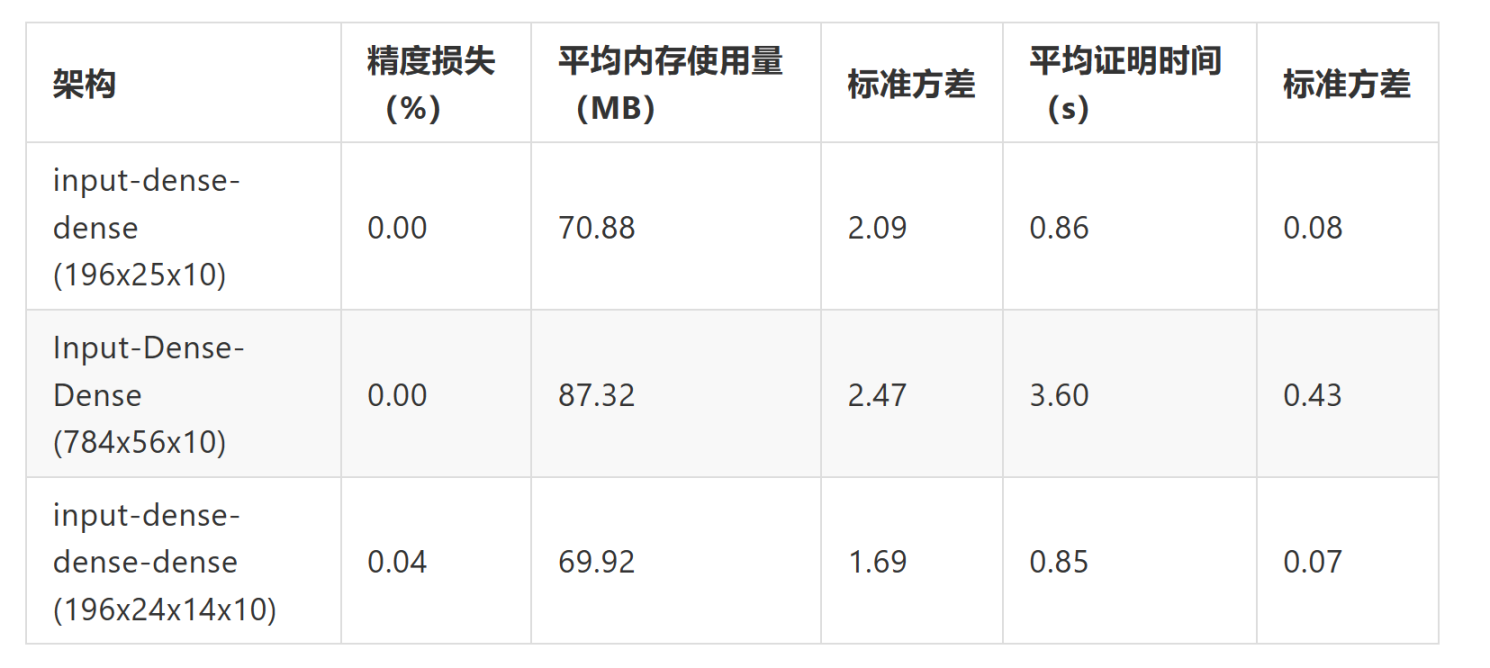
以下是 opML 在 DNN 模型上的性能指标列表:
CNN 模型性能
在下面的条形图中,我们展示了每个框架在各个具有不同网络规模的 CNN 模型上的性能结果,涵盖了之前的三个指标。
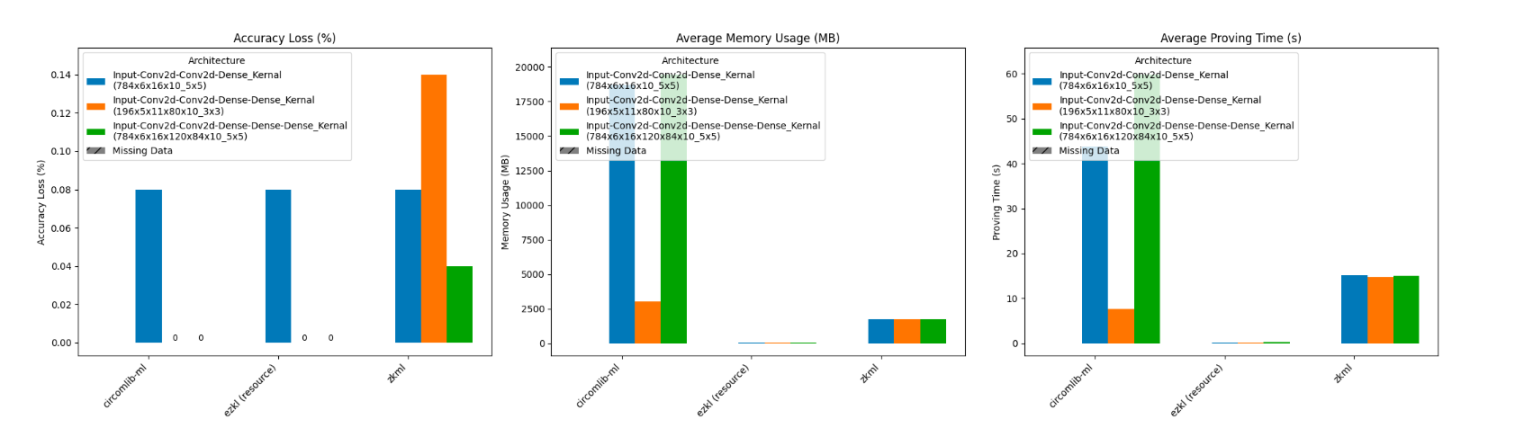
接下来,我们对这些结果进行了归一化,并通过雷达图进行了呈现。由于 opML 目前不支持 Conv2d 操作符,因此本轮基准测试只评估了三个框架。雷达图清楚地表明,EZKL 即使在「resource」模式下,也在所有三个指标上占据了主导地位。
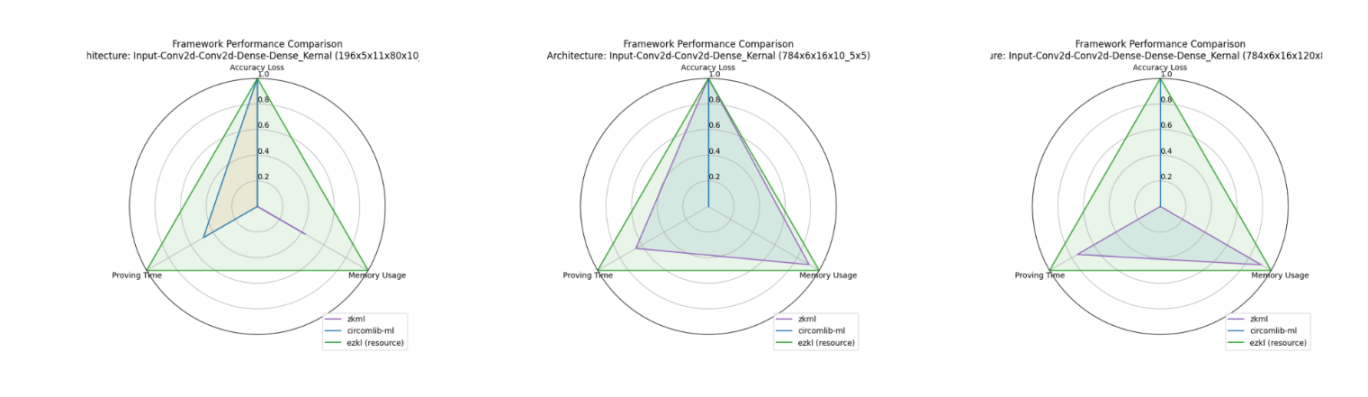
Here’s the translation of your「Analysis」section, along with refinements to enhance clarity and flow:
分析
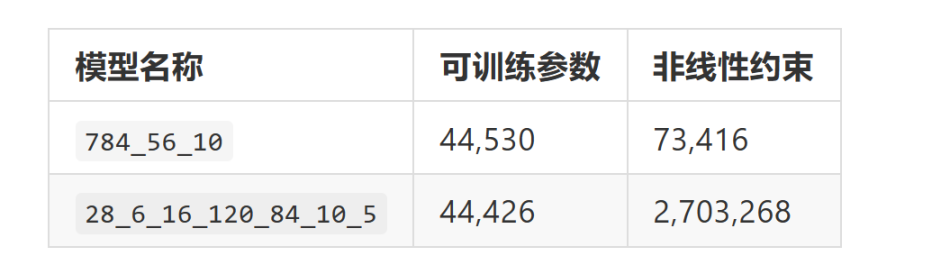
我们将通过六个独特的神经网络模型进行深入的性能分析,并探讨结构变化如何影响精度损失、内存使用量和证明时间这些关键指标。因此,我们设计了 4 种变化,来细致观察其产生的性能波动。
以为各模型的相关参数,并将用于之后的分析:
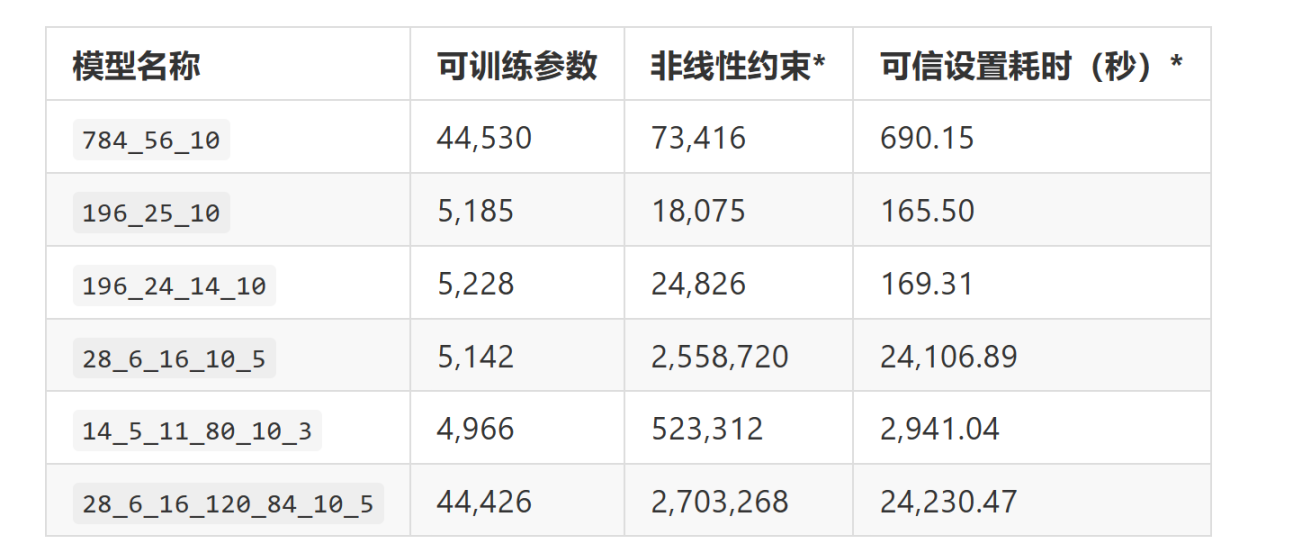
注意:「非线性约束」(non-linear constraints)和「可信设置耗时」(trusted setup)这两个指标专门针对 Circomlib-ml 框架,因其使用 Groth16 证明系统来生成零知识证明,所以需要进行可信设置。
改变 DNN 中的层数
为了探究框架对增加的层数的敏感度,我们选取了参数量几乎相同,但层数不同的模型进行了性能分析:
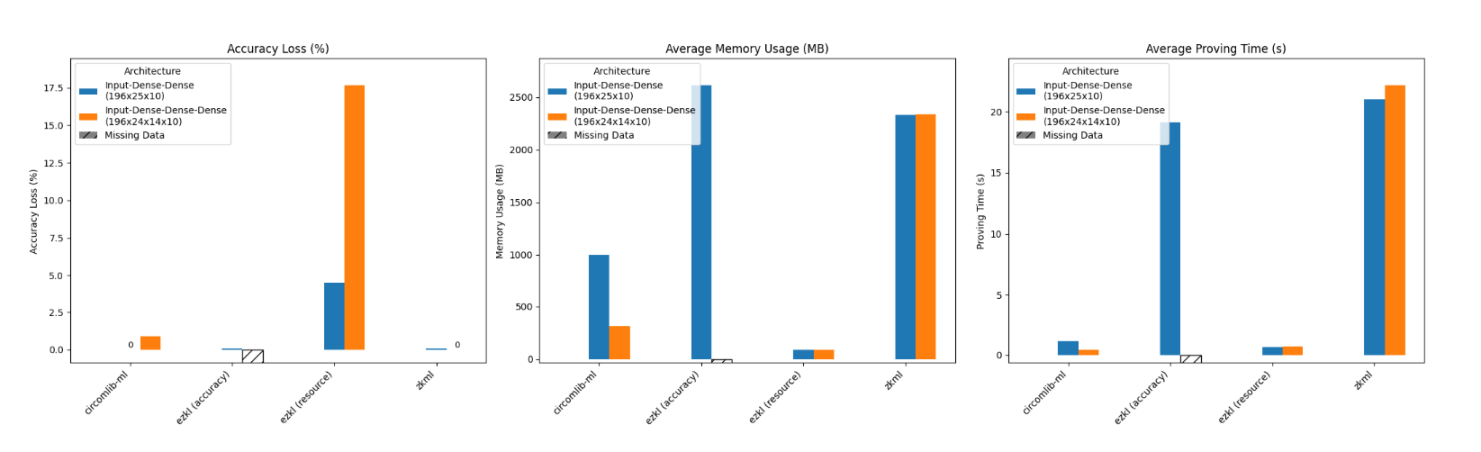
条形图显示,在资源模式下运行的 EZKL 框架,其精度损失显著上升。令人意外的是,尽管非线性约束数量更多,Circomlib-ml 的内存使用量却有所降低,这与预期的「复杂度越高、资源消耗越大」的趋势相悖。
改变 DNN 中的参数数量
将模型从 ‘196_25_10’ 增加到 ‘784_56_10’,也就是增加参数数量,会导致内存使用量和证明时间的预期增长,但 Daniel Kang 开发的 zkml 框架保持了性能稳定。
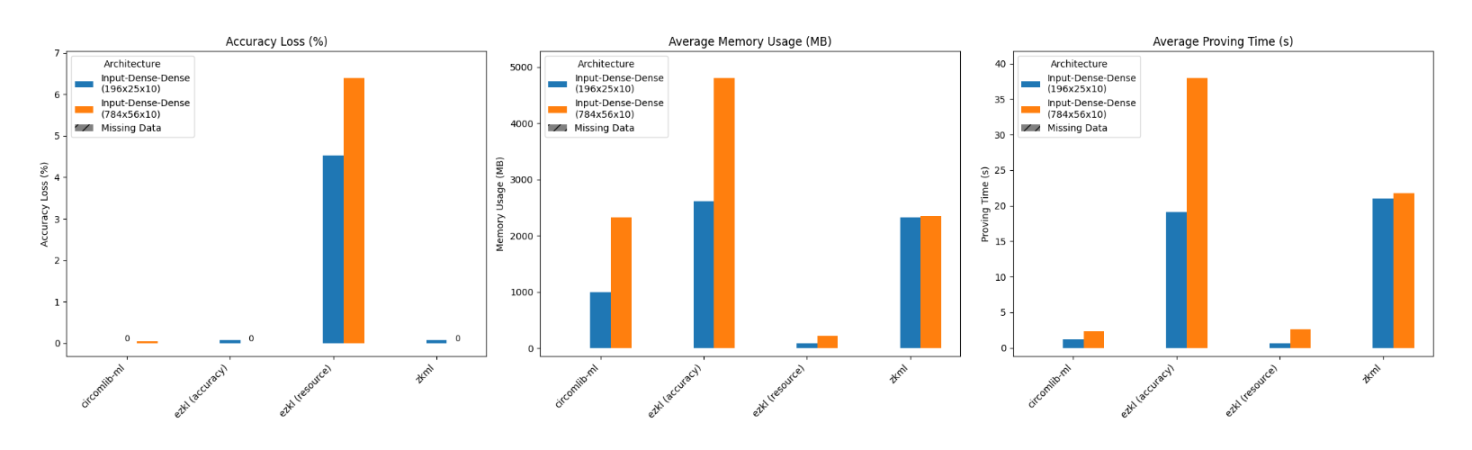
把 Conv2d 层变为 Dense 层
将测试模型中的 Conv2D 层替换为 Dense 层,让我们看到了不同 zkML 框架的适应能力差异。
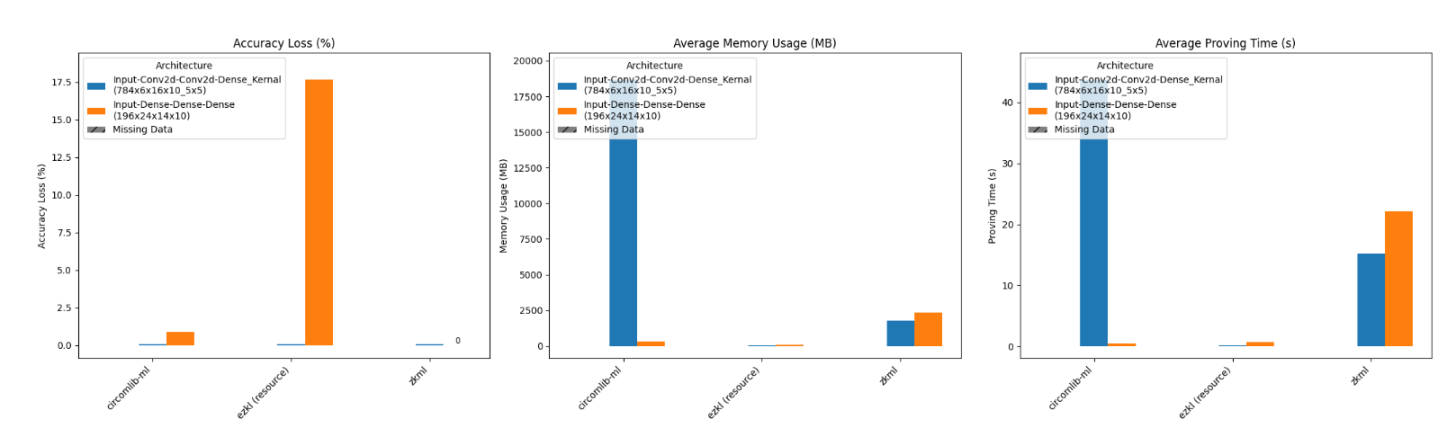
尽管这两个模型具有大致相同数量的可训练参数和层数,但上面的条形图表明这种改变导致了显著的性能差异。 具体而言,ezkl 的精度损失从 0.0% 飙升至 17.68%,zkml 的证明时间增加了 50.64%(从 14.715 秒增加到 22.168 秒),而只有 Circomlib-ml 从这种结构变化中获益。
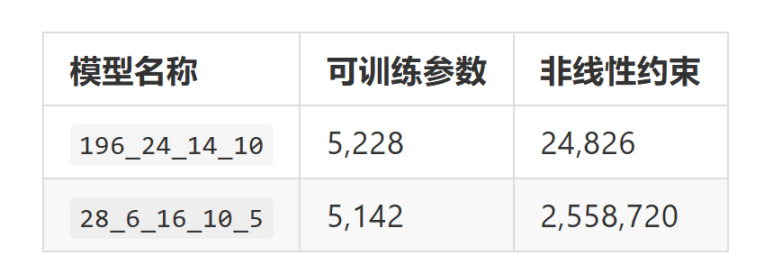
下表列出了非线性约束方面的差异,可能有助于解释 Circomlib-ml 性能提升的原因:
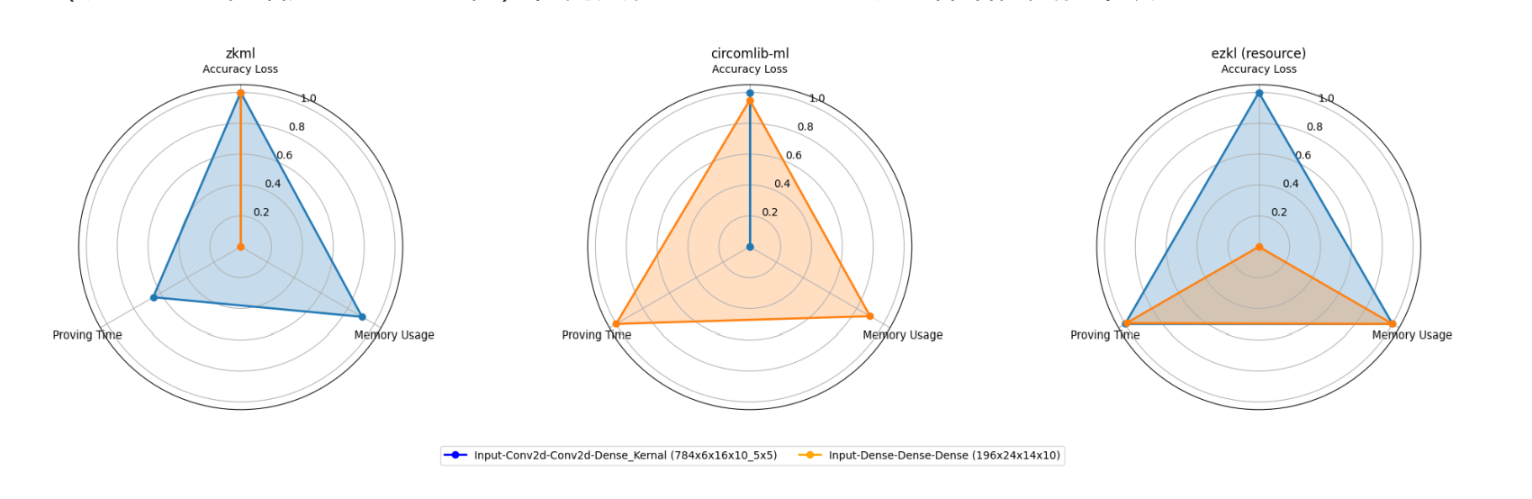
这种性能差异进一步体现在雷达图中,zkml 和 ezkl 的性能区域在以最佳表现的框架进行归一化后都出现了收缩。
移除 Conv2d 层
当移除两个 Conv2D 层和一个 Dense 层时,我们观察到了类似的趋势。简化架构并保持参数数量,直觉上看会让网络更加精简,但实际上却导致了显著的性能下降。这表明这两个框架,尤其是资源模式下的 ezkl,更适合包含 Conv2d 层的神经网络。
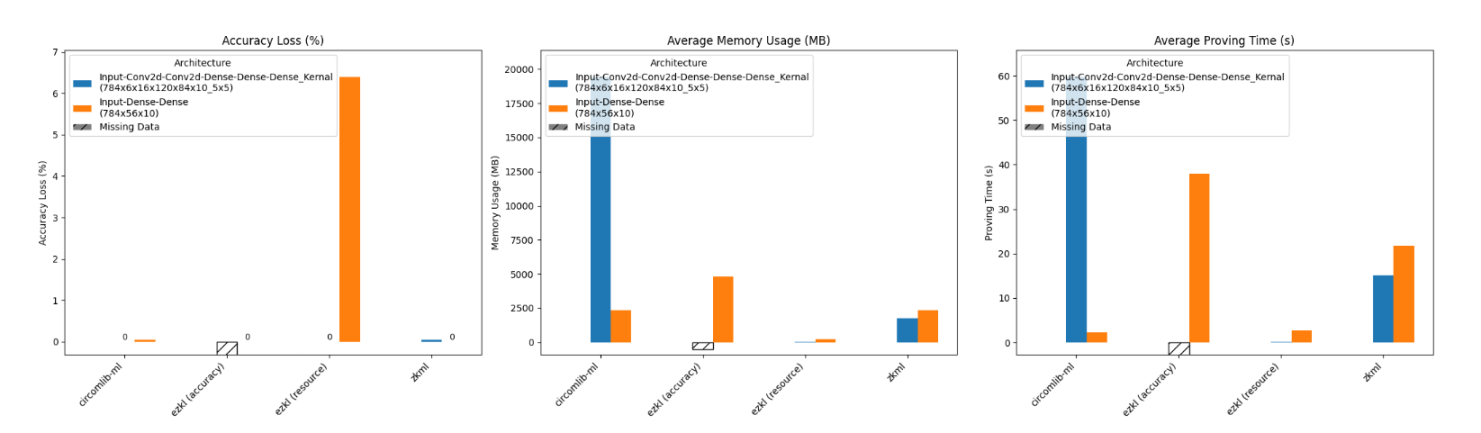
如上图所示,这种变化也体现在了雷达图的归一化数据中。
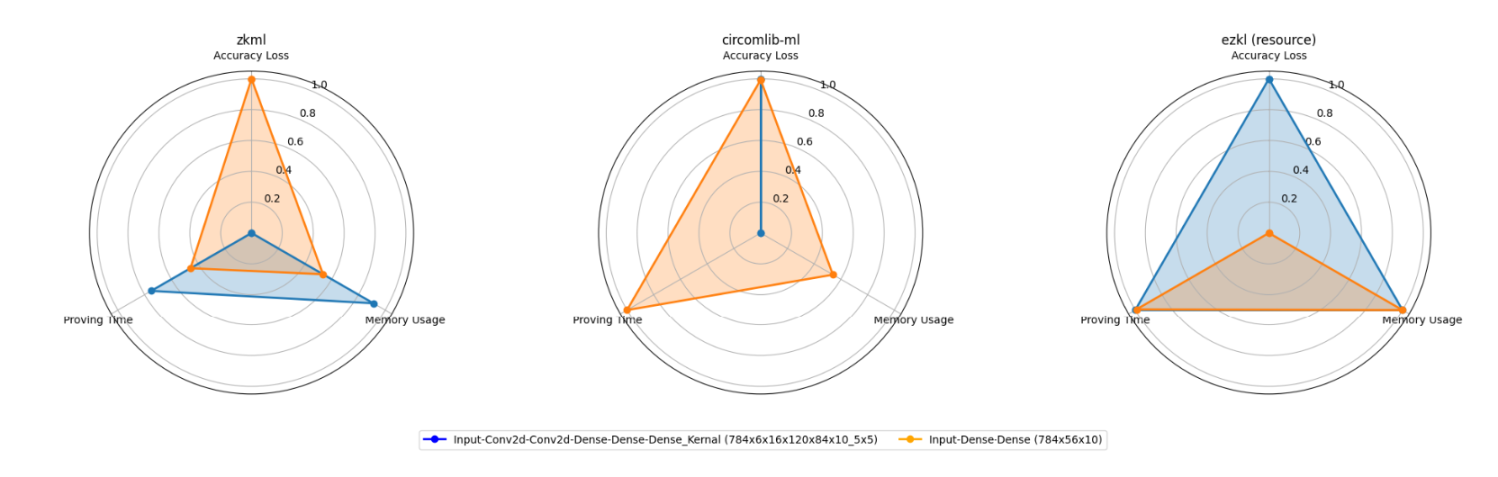
此外,非线性约束的大幅减少再次解释了 Circomlib-ml 的性能提升原因。
Here’s a translation of your「Summary」section, with some refinement for better flow and clarity in Chinese:
总结
在此基准测试项目中,我们严格地评估了四种知名的 zkML 框架在六种 DNN 和 CNN 神经网络架构上的表现。我们的分析揭示了对这些框架的性能表现的几个可能的原因。如需查看我们测试结果的详细报告,请参阅此链接中的完整版报告
一个重要发现是,zk-SNARKs 和 Halo2 这两种 zk 系统在性能上有显著差异,特别是在处理神经网络时。Circomlib-ml 将 ‘Conv2d’ 转译为电路的做法似乎造成了显著的资源消耗,与之形成对比的是,EZKL 和 DDKang ZKML 则更多地受到层数和网络参数变化的影响。
此外,opML 框架的系统在图像分类任务中展现了相当可观的潜力。尽管目前在 operator 支持方面有所局限,该框架在 DNN 模型上的表现表明,依然可将其视为传统 zkML 框架的有力替代方案,尤其是在对「任意信任」(any-trust)的保证就已足够的情况下——即单个诚实的验证者即可强制执行正确的行为。
本基准测试未涉及的一个关键方面是缩放因子(scaling factor)对精度损失的影响。我们为每个框架使用了默认设置:
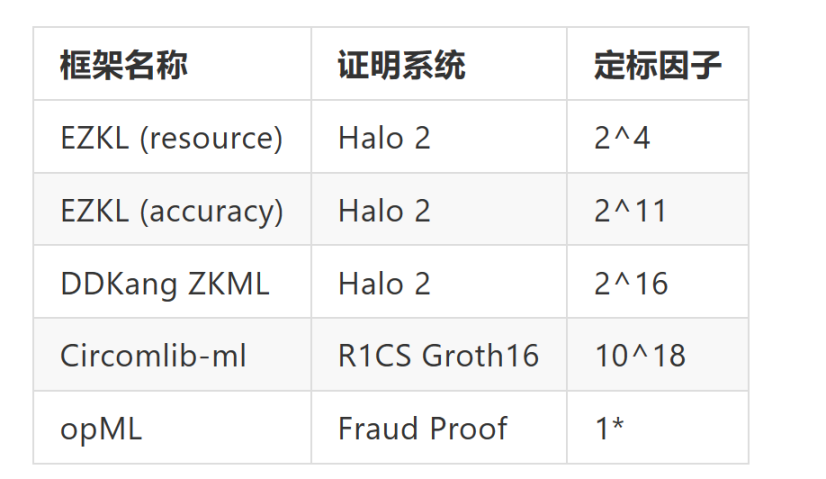
1*: 由于 opML 使用的虚拟机支持浮点计算,此处无需缩放。
值得注意的是,EZKL 在精度模式下在 DNN 模型上实现了完美精度,而其资源模式下的表现不佳,这凸显了缩放因子的重要性。然而,尽管具有更高的缩放因子并采用相同的证明系统,Daniel Kang 的 DDKang ZKML 在精度上并没有优于 EZKL。这提出了一个关键问题:或许存在一个最佳的缩放因子,能够同时使性能和精度达到一种平衡。
(声明:请读者严格遵守所在地法律法规,本文不代表任何投资建议)
