
导语:近期 Vitalik 和一些学者联名发表了新论文,其中提到了 Tornado Cash 如何实现反 xi 钱方案(其实就是让取款人证明,自己的存款记录属于一个不包含黑钱的集合),但文中缺乏对 Tornado Cash 业务逻辑与原理的细致解读,让人似懂非懂。
此外值得一提的是,Tornado 为代表的隐私项目才是真正用到了 ZK-SNARK 算法的零知识性,而大多数打着 ZK 旗号的 Rollup,用到的只是 ZK-SNARK 的简洁性。很多时候人们往往混淆了 Validity Proof 与 ZK 的区别,而 Tornado 恰好是理解 ZK 应用的极佳案例。
本文作者恰好在 2022 年于Web3Caff Research写过一篇关于 Tornado 原理的文章,今日将其部分段落节选并拓展,整理成文,以便大家系统的理解 Tornado Cash。

「龙卷风」的原理
Tornado Cash 是利用了零知识证明的混币器协议,旧版本在 2019 年投入使用,新版本在 2021 年底启动了 beta 版。Tornado 旧版本基本实现了去中心化,链上合约开源且无多签控制,前端代码开源且备份在了 IPFS 网络里。由于旧版 Tornado 的整体结构更简单易懂,所以本文将针对旧版本进行解读。
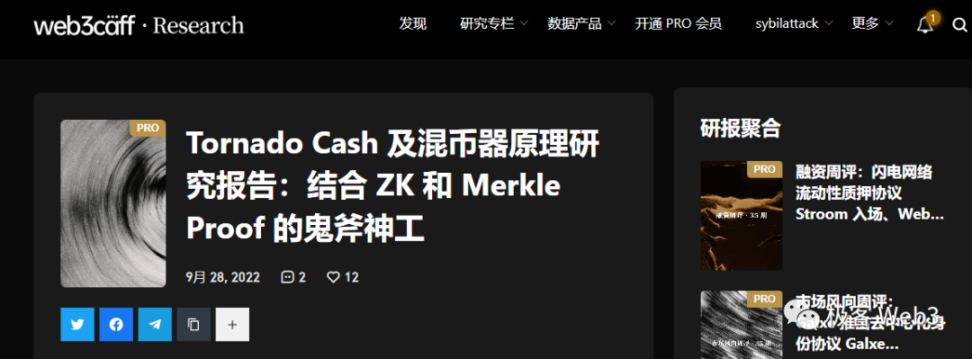
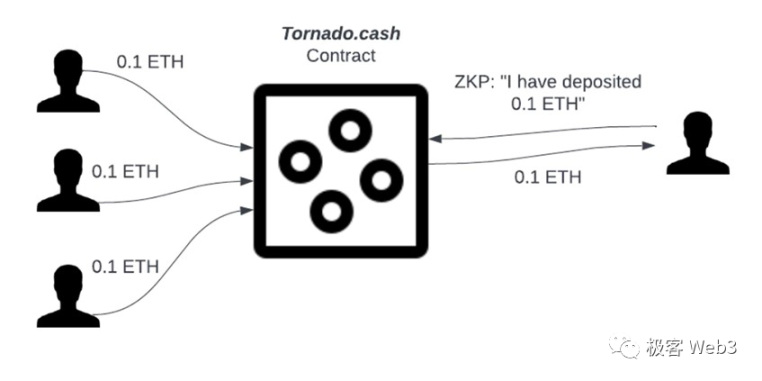
Tornado 的主要思路是:把大量的存取款行为混杂在一起,存款者在 Tornado 存入 Token 后,出示 ZK Proof 证明自己存过款,再用一个新地址提款,以此切断存取款地址之间的关联性。
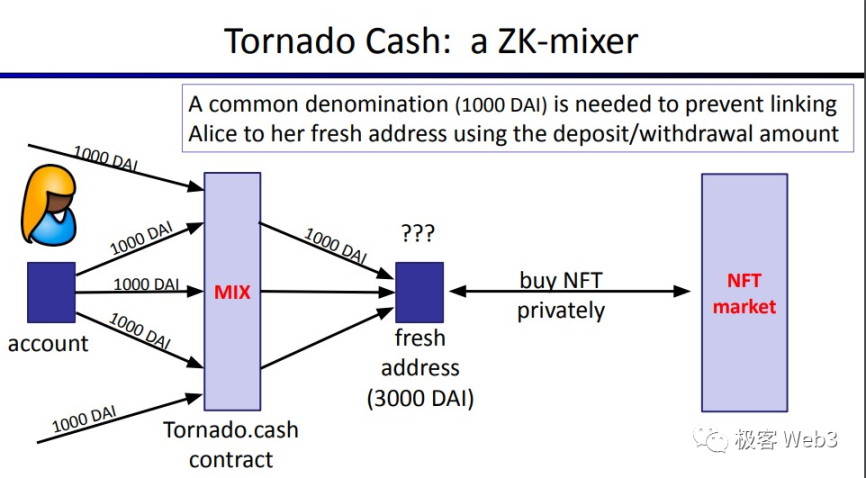
更具体的概括,Tornado 就像一个玻璃箱,混杂了很多人放进去的 Coin 硬币。我们能看到放 Coin 的是哪些人,但这些 Coin 高度同质化,如果有生面孔的人从玻璃箱拿走一枚 Coin,我们很难知道他拿走的 Coin 最初是谁放进去的。
(图源:rareskills)
这种场景似乎屡见不鲜:当我们从 Uniswap 池子里 SWAP 几枚 ETH 时,根本无法知道划走的 ETH 是谁提供的,因为曾给 Uniswap 提供流动性的人太多了。但不同之处是,每次用 Uniswap 划走 Token,我们需要用其他 Token 作为等价的成本,且不能把资金「私密的」转让给别人;而混币器只需要提款者出示存款凭证就行。
为了让存取款动作看起来有同质性,Tornado 池子的存款地址每次存入的资金、取款地址每次取出的资金都保持一致,比如某个池子的 100 个存款者和 100 名取款者,虽然公开可见,但看起来彼此没有任何联系,而且每人存入的金额、取出的金额,都是一样的。这时就可以混淆视听,没法按照存取款金额判断关联性,进而切断资金转移痕迹,显而易见的是,这为 xi 钱行为提供了天然的便利。
但有一个关键问题:取款者在提款时,怎么证明自己存过款?向混币器发起取款的地址,与所有的存款地址都不关联,那么该如何判断他的提款资格?看起来最直接的方法,是取款者直接披露自己的存款记录是哪一笔,但这就直接泄露了身份。此时零知识证明就派上了用场。
提款者出具一个 ZK Proof,证明自己在 Tornado 合约里有存款记录,且该笔存款尚未被提取,就能顺利发起取款。零知识证明本身就实现了隐私保护,外界只知道:取款人的确往资金池里存过款,但不知道他对应哪个存款者。
要证明「我在 Tornado 资金池里存过款」可以被转化为「我的存款记录可以在 Tornado 合约里找到」x。如果用 Cn 表示存款记录,问题就归纳为:
已知 Tornado 的存款记录集合为{C1,C2,…C100…},取款者 Bob 证明自己曾用手上的密钥,生成了存款记录里的某个 Cn,但通过 ZK 不泄露 Cn 具体是哪个。
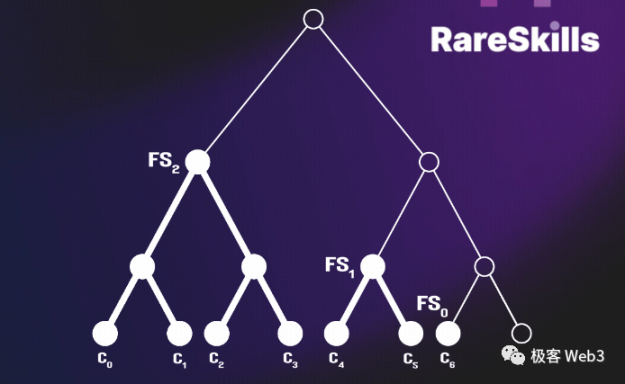
这里要用到 Merkle Proof 的特殊性质。因为Tornado 的所有存款记录,都存进了链上构造的一棵 Merkle Tree,作为其最底层的叶子结点,而叶子总数约为 2 的 20 次幂>100 万,大多数都处于空白状态(赋予了初始值)。每当有新存款行为产生时,合约就会把其对应的特征值 Commitment 写入一个叶子里,然后更新 Merkle Tree 的 root。
比如,Bob 的存款操作是 Tornado 有史以来第 1 万笔,那么与这笔存款有关联的一个特征值 Cn 会写入 Merkle Tree 的第 1 万个叶子结点,也即 C10000 = Cn。然后合约会自动算出新的 Root,update 一下。(ps:为了节约计算量,Tornado 合约会缓存之前一批有变化的节点的数据,比如下图中的 Fs1 和 Fs2、Fs0)
(图源:RareSkills)
而Merkle Proof 本身很简洁轻便,它利用了树状数据结构在检索 / 溯源过程中的简洁性。若想对外证明某笔交易 TD 存在于 MerkleTree 中,只要给出 Root 对应的 MerkleProof(如下图中右边的部分),它相当简洁。如果 Merkle Tree 格外庞大,底层叶子有 2 的 20 次幂个,也就是包含 100 万笔存款记录,Merkle Proof 也只需要包含 21 个节点的数值,非常短。
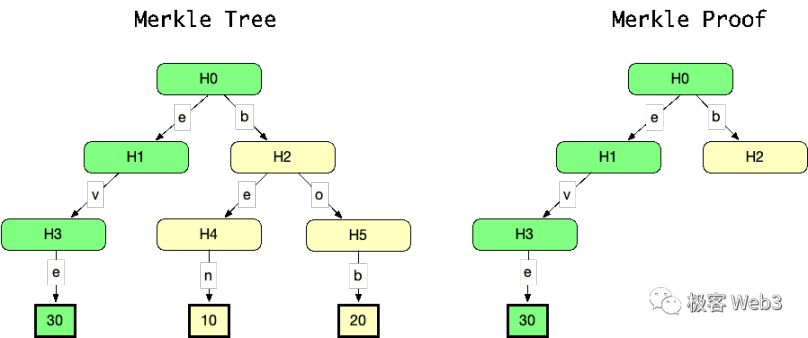
如果要证明某笔交易 H3 的确包含在 Merkle Tree 中,设法证明用 H3 和 Merkle Tree 上其他的部分数据,可以生成 Root,而生成 Root 所需要的那部分数据(包括 Td 在内)就构成了 Merkle Proof。
而 Bob 在取款时,要证明自己拥有的凭证对应着 Merkle Tree 上有记录的某笔存款哈希 Cn。也就是说,他要证明两件事:
- Cn 存在于链上 Tornado 合约里的 Merkle Tree 中,具体可以构造一个 Merkle Proof,里面包含 Cn;
- Cn 与 Bob 手上的存款凭证有关联。
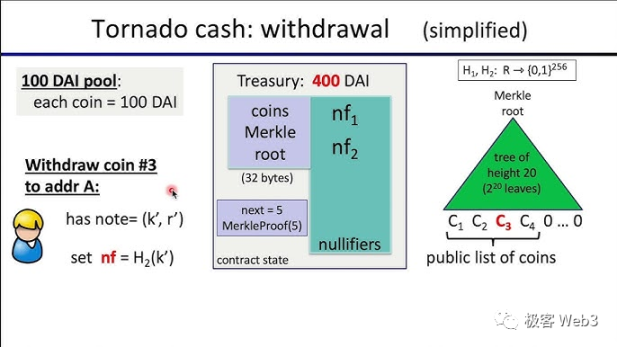
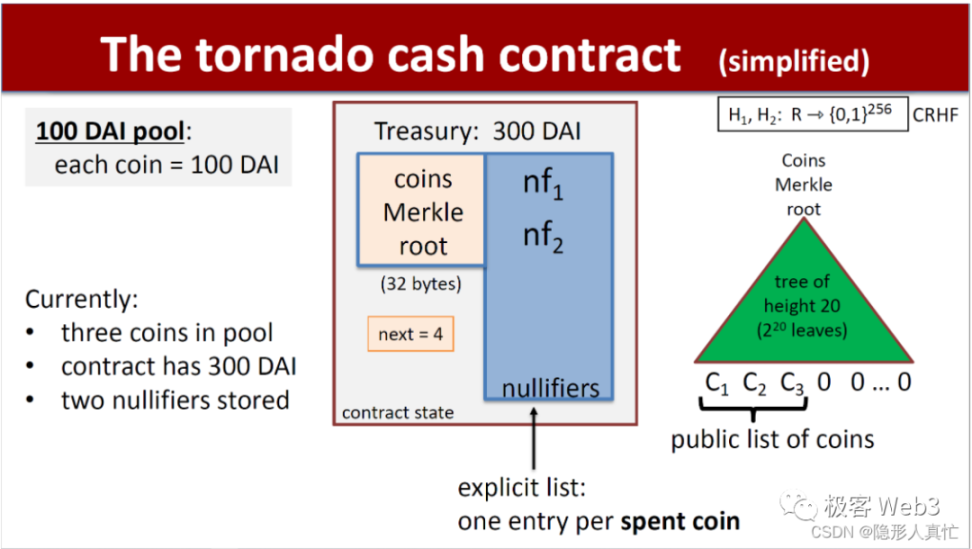
Tornado 业务逻辑详解
Tornado 用户界面的前端代码中事先实现了很多功能,当一名存款者打开 Tornado Cash 网页并点击存款按钮后,前端代码附带的程序会在本地生成 2 个随机数 K 和 r,随后会计算出 Cn=Hash(K,r) 的值,再把 Cn(就是下图中的 commitment)传入 Tornado 合约,插入到后者记录的 Merkle Tree 里。说白了,K 和 r 相当于私钥。它们很重要,系统会提示用户妥善保存。后面提款时仍然要用到 K 和 r。
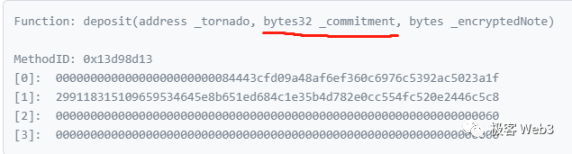
(此处的 encryptedNote 是可选项,允许用户把凭证 K 和 r 用私钥加密,存储到链上,防止遗忘)
值得注意的是,以上工作皆发生于链下,也就是说:Tornado 合约和外界观察者都不知晓 K 和 r。如果 K 和 r 被泄露了,就类似于钱包私钥被盗。

Tornado 合约收到用户存款,并收到用户提交的 Cn=Hash(K,r) 后,便将 Cn 插入到 Merkle 树的最底层,作为新的叶子结点,同时会更新 Root 的数值。所以,Cn 和用户的存款动作是一对一关联的,外界可以知道每个 Cn 对应着哪个用户,知道有哪些人往混币器里存入了 Token,并且知道每个存款者对应的存款记录 Cn。
在取款步骤中,取款者在前端网页里输入凭证 / 私钥(存款时生成的随机数 K 和 r),Tornado Cash 前端代码中的程序会使用 K 和 r、Cn=Hash(K,r)、Cn 对应的 Merkle Proof 作为输入参数,生成 ZK Proof,证明 Cn 是存在于 Merkle Tree 上的某笔存款记录,而 K 和 r 是对应 Cn 的凭证。
这一步就相当于证明:我知道某笔记录于 Merkle Tree 上的存款记录对应的密钥。当 ZK Proof 被提交给 Tornado 合约时,上述 4 个参数均被隐藏,外界(包括 Tornado 合约)无法获知,借此保障了隐私。
生成 ZKProof 涉及的其他参数还包括:取款时 Tornado 合约里 Merkle Tree 的根 root、自定义的收款地址 A、防止重放攻击的标识符 nf( 后面会讲 )。这 3 个参数会公开发布到链上,外界可以获知,但不影响隐私。
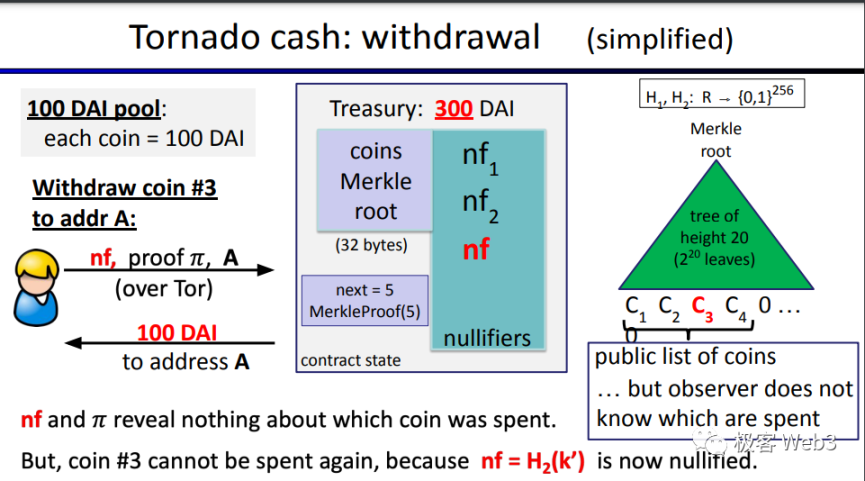
这里面有个细节,就是存款操作生成 Cn 时,用了 2 个随机数 K 和 r 来生成 Cn,而不是单个随机数。这是因为单个随机数不够安全,有一定概率发生碰撞,比如,采用单随机数可能导致两个不同的存款者恰巧采用 1 个同样的随机数,导致生成的 Cn 撞车。
至于上图中的 A,代表接收提款的地址,由提款者自己填写。nf 则是一个防止重放攻击的标识符,其数值 nf=Hash(K),K 就是存款生成 Cn 那一步用到的 2 个随机数之一(K 和 r)。这样一来,nf 就与 Cn 关联了起来,换言之,每个 Cn 都有对应的 nf,两者一一关联。
为什么要防止重放攻击呢?由于混币器在设计上的特性,取款时不知道用户提走的币对应 Merkle 树的哪个叶子 Cn,也就不知道提款人和哪些存款人关联,就不知道提款人到底存过几次款。提款者可以利用这一特性频繁提款,发起重放攻击,多次从混币器池里取走 Token,直到把资金池抽干。
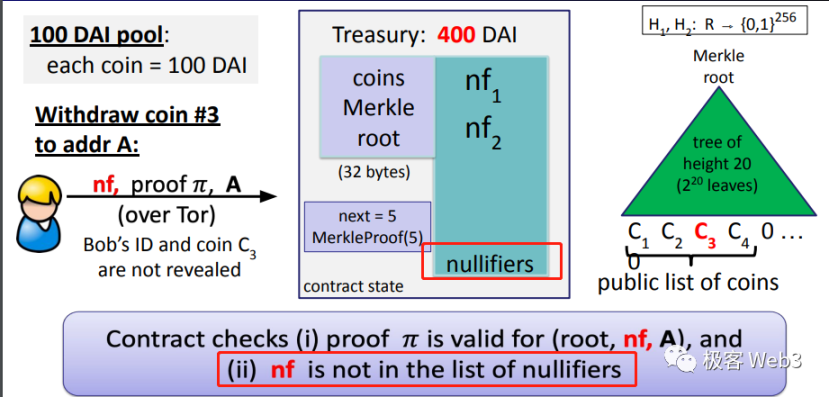
在这里,nf 标识符的作用类似于每个以太坊地址都有的交易计数器 nonce,都是为了防止某笔交易被重放而设置。当一笔取款发生时,取款者需要提交一个 nf,检查这个 nf 是否已被使用过(记录在案):如果有,此次取款无效。如果没有,表示该 nf 尚未被使用,取款有效,对应的 nf 会被记录下来。下次再有人提交这个 nf 时,对应的取款动作直接判定为无效。

如果有人胡乱生成一个合约没记录过的 nf 行不行?当然不行,因为取款者生成 ZK Proof 时,需要保证 nf=Hash(K),而随机数 K 与存款记录 Cn 关联,也就是说,nf 与某笔有记录的存款 Cn 关联。如果随便编造一个 nf,这个 nf 与存款记录中的所有存款都对不上号,就不能顺利生成有效的 ZK Proof,后续的工作就无法顺利完成,取款操作就不会成功。
可能也有人会问:不用 nf 行不行?既然提款者在提款时需要提交 ZK 证明,证明自己和某个 Cn 有关联,那么每当提款动作发生时,查找对应的 ZK Proof 是否被提交到链上过,不就行了吗?
但事实上,这样做的成本很高,因为 Tornado cash 合约不会永久存储过去提交的 ZK Proof,因为这会严重浪费存储空间。与其比较每个新交到链上的 ZKProof 和既有的 Proof 是否一致,还不如设置个占地很小的标识符 nf 并将其永久存储来的更划算。
按照取款函数的代码示例,其需要的参数和业务逻辑如下:
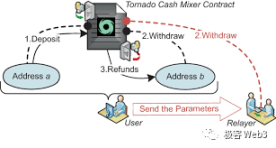
用户提交 ZKProof、nf(NullifierHash)=Hash(K),自定义一个接收提款的地址 recipent,ZKProof 隐藏了 Cn 和 K、r 的数值,让外界无法获取判断用户身份。recipent 往往会填写一个干净的新地址,也不会泄露个人信息。
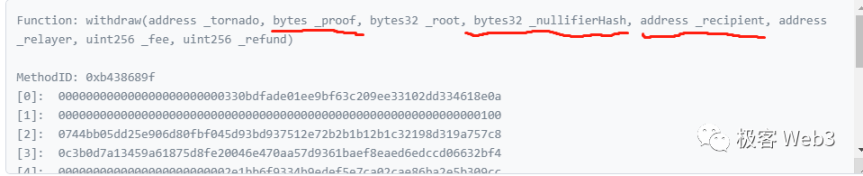
但这里面有个小问题,就是用户在取款时,为了不可溯源,往往用新申请的地址发起取款交易,此时新地址没有 ETH 来支付 gas 费。所以取款地址发起取款时,要显式声明一个中继者 relayer,由它代付 gas 费,之后混币器合约会直接从用户提款里扣掉一部分交给 relayer,作为回报。

综上所述,TornadoCash 可以隐瞒取款者与存款者的关联,在用户量很大的情况下,就如同一个闹市区,犯人混进人群后警方就难以追踪。取款过程中需要用到 ZK-SNARK,被隐藏起来的 witness 部分包含取款人关键信息,这是整个混币器最关键的一点。目前看来,Tornado 可能是与 ZK 相关的最巧妙的应用层项目之一。
(声明:请读者严格遵守所在地法律法规,本文不代表任何投资建议)
