
中间件安全性问题
现有的 Indexing 协议和 Keeper 网络都不是完全 trustless 的, 而是 trusted, 或者看似 trustless 的. 开发者和用户需要以 “Trust, Not Verify” 的方式来信任这些产品不会作恶.
它们都是上一代的基础设施, 在当时可能确实没有太好的解决方案, 所以用了 Fisherman 机制或者 DAO 治理 (Social Consensus…), 来保证数据的可信和协议的安全运行.
在当前, 各个 zk 方案已经进入性能优化的收尾阶段, 这些前朝的剑, 就不能再来斩本朝的官了. 通过 zk, 可以实现 Web3 中间件的所有革新, 确保安全性, 去中心化, 和性能被同时满足, 就如同 Optimistic Rollup 在未来很可能会被 zk Rollup 抢走 Layer2 的主导地位一样.
Web3 Indexing
a) Web3 索引
我们首先需要了解为什么需要 Web3 特制的索引协议:
- Web3 是地址模型, 智能合约数据以交易形式存在, 需要索引来让数据结构更加易用; Web2 的数据结构开发者自己处理.
- Web3 的很多数据都是交易相关数据; Web2 被索引的数据很大一部分都是搜索引擎索引的网页或者图片等数据.
- Web3 需要通用索引协议来发挥可组合性; Web2 开发者自己根据自己的中心化应用搭建索引服务.
对于这几点, 如果你在 DApp 的开发中, 硬是要自己来进行索引, 那么每当去提取合约中的特定数据, 需要非常大的前端代码量, 以下是一个例子, 真的要建立一套服务的话需要无数个不同的函数:
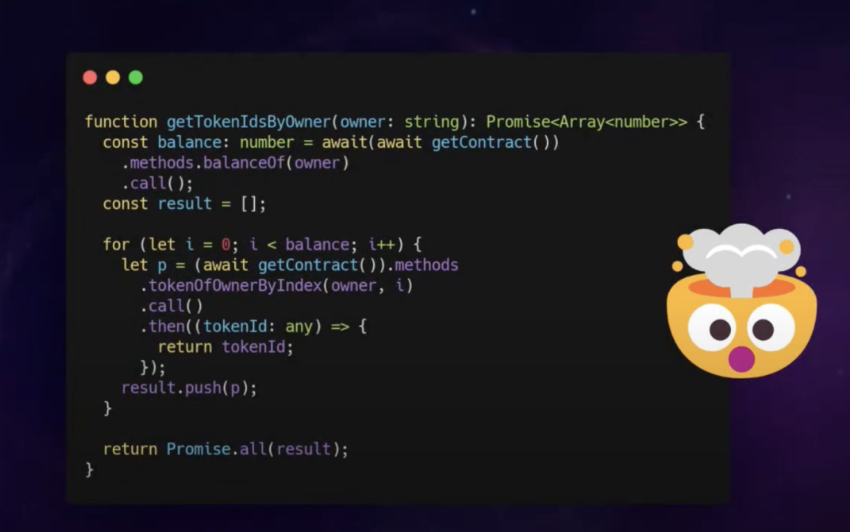

于是在我们之前的 DApp 架构图中, 前端要使用和获取智能合约的数据时, 就必备一个通用的 Indexing 协议作为中间层, 来让智能合约的数据能被前端所轻松使用.
b) GraphQL 索引
我们需要一个 Indexing 协议作为中间层, 那么这个协议该如何选型呢 (The Graph 19 年有讲过 Web3 为什么要用 GraphQL, 但是感觉说得不太清楚)? 我们有四个潜在选择.
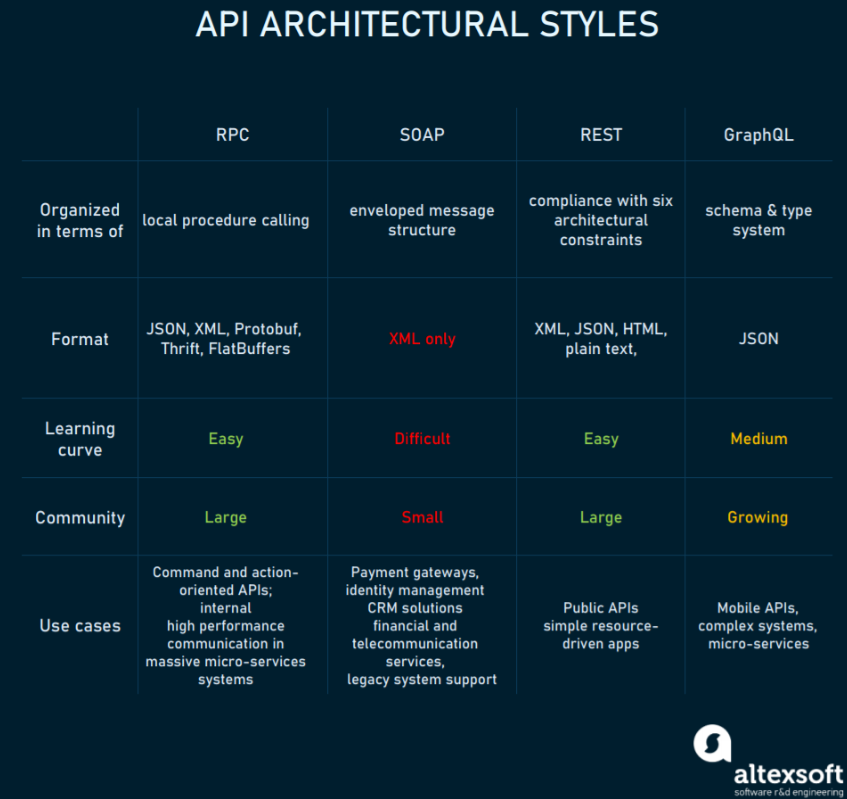
首先, 排除 SOAP. 因为它的采用率非常少, 学习曲线也非常陡峭. 甚至有人说 “REST is king, and SOAP is trash”.
其次, 排除 RPC. RPC 是客户端对区块链, 或者 Web2 服务与服务之间的常用调用规范, 以操作 (动词) 为核心, 接口的更新更加麻烦一些, 适合客户端与区块链网络的通信. 但对于我们的智能合约开发场景来说, 太重, 不是最适合, 性能也因为请求数量多, 和需要依赖正在运行的程序, 而导致不太好.
接着, 排除 REST. REST 风格算是以资源 (名词) 为核心来操作的规范. 但是 Web3 应用中, 对任何资源进行更新操作的动作都需要用户或者其他方授权触发, 我们在索引协议中的请求全部是 GET 请求, 那就没必要 REST 了.
最后, 选择了 GraphQL:
- GraphQL 协议本身的构建工作量相比其他标准更小, 更不需要变化, 更容易搭建通用的协议.
- GraphQL 的交互形式给了前端更多的自由度, 由前端定义结果, 符合 DApp 结构中的无后端思想.
- GraphQL 非常适合区块链中完全开放且不易变, 同时有非常多树状结构数据的智能合约场景, 性能上也会因此更好.
- GraphQL 在区块链中已经有 The Graph 针对单个智能合约的索引制定了成熟标准, 也早就有对整条链的 GraphQL 接口 (ethql, Clear), 成熟度高, 开发者生态也被培养得很好.
除此之外, 我并不认为我们需要花非常多的时间去开发新的存储网络的 GraphQL 协议和 Query 协议 (当然这些索引的聚合是有意义的):
- 存储网络大多都自带可用的索引协议, 如 Arweave 的 GraphQL 服务, 开发新的协议是在重复造轮子.
- 存储网络上的数据相对于合约数据或者 Web2 数据量都非常小, 同时所承载的价值也相对来说更小.
- Web2 已经有更加成熟的协议和方案来进行这些数据的索引, 开发新的协议依然类似是重复造轮子.
当我们讨论索引协议的时候, 默认的都是从前端直接获取区块链智能合约的数据, 这是因为我们在前文中就阐述过, 消除后端服务器对 Web3 Crypto-native 可信 DApp 的意义.
硬要加上针对智能合约链的后端的话反而徒增架构复杂度和暴露更多的不可信因素 (目前有 zk-sql 等项目在专注于相关问题, 但无法完全解决; 也有 Sqlidity 这样有趣的链上 SQLite 方案), 当然对于基于存储协议的 DApp 来说, SQL 化的语句对开发熟悉度和流程来说是有必要的.
索引协议需要关注的结构应该是前端能直接使用的 GraphQL 结构.

c) 现有 Web3 GraphQL 索引协议问题
现有的 Indexing Protocol 的龙头必然是去中心化的 The Graph 和 Pocket Network 和中心化的 Alchemy. 无论是中心化还是去中心化, 它们都各有各的问题:
- 中心化 Indexing Protocol 问题:
- 无法抗审查
- 无法保证服务高可用性
- 现有去中心化 Indexing Protocol 问题:
- 信任模型和安全性依旧差 (攻击 Subgraph 的成本非常低, 机制和 Chainlink 2.0 一样, 是靠 “更可信” 的 Fisherman 来举报)
- 性能无法满足需求
对于安全性的问题, Fisherman 机制在 Optimistic Rollup 中的体现与 Indexing Protocol 所不同, Optimistic Rollup 的数据是链上的, 更大的群体可以通过执行轻松验证, 而 Indexing 的过程是链下的, 如果并非 Subgraph 的 indexer 的话, 很难去对错误数据进行挑战. 这就导致信任模型更不稳固.
这几个缺陷结合在一起, 就导致了大的 DeFi 应用因为性能和安全性而很少使用这些索引协议, 这个市场有着巨大的空缺.
d) ZK 解决智能合约索引协议问题
ZK 其实是个非常好的解决方案, 任何的 Optimistic 机制的问题都可以通过转为 ZK 来解决, 比如 Rollup 这个最显著的领域.
ZK 化之后的索引协议兼具了中心化和去中心化协议的所有优点, 包括高可用性和抗审查 (多个节点保证 uptime), 性能极佳 (因为 ZK 的存在所以可以选用中心化高性能节点), 安全性 (ZK 的数学密码学很好地保证安全性)
对于一个索引协议来说, ZK 的方案:
- 不需要 EVM 兼容性.
- 注重整体性能, 需要保证 Verifiable Query 的速率.
The Graph 自己也意识到了自己的机制安全性的不足, 正在琢磨 Shellproof.
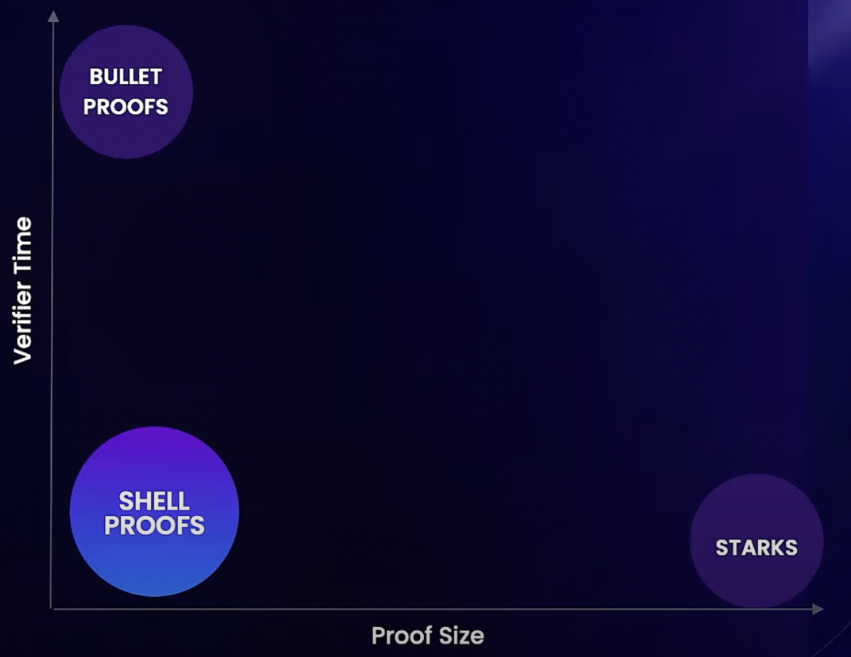
但是我认为 The Graph 目前的研究和开发进度还是慢, 不知道 Shellproofs 是否能支持全部 subgraph 的运行. 而且 The Graph 已经在现有的机制上花了这么多功夫, 去替换这个机制的难度甚至比重新建立一套还要高.
一个真正实现了 zk 化的 The Graph 的应用可以构建出新的应用与开发范式:
- 任何 DeFi 应用都可以信任这个索引协议的数据, 大大简化了开发流程.
- 多链应用可以同时可信使用多链和多协议的数据, 用户体验上会得到巨大提升 (+ Standardized Subgraph).
通过这样的思路, 我们可以理解 zk 化的 The Graph 实际上是一个去中心化 RPC, 这远比 The Graph 的叙事宏大, 而是真正能实现 Infura 所在追求的去中心化.
Web3 Keeper Network
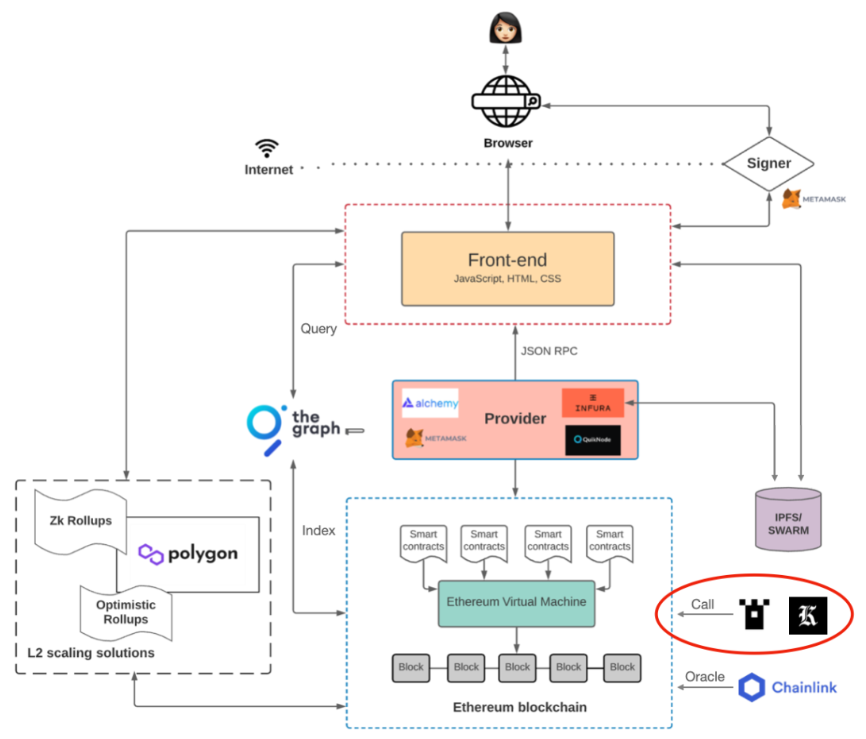
在之前 Crypto-Native 应用架构的文章中, 我们提到过 Keeper.
它本质上就是, 一个链下定时器到了特定时间就触发智能合约的某个功能, 类似:
- Linux 里的 CronJob
- Web API (不是 JS) 里的 setTimeout 和 setInterval
它的用处具体包括:
- 链上预言机价格更新 (之前提到的 Uniswap V2 TWAP)
- 交易, 投票, 清算机器人
- 自动化挖提卖
然而, 和我们之前提到的 The Graph 类似, 它的安全性机制是很落后的, 甚至还不是 The Graph 这样的链上治理, 而是链下通过 DAO 和 Social Consensus 的举报机制人工检举揭发非法节点. 比如下图中, Gelato 的架构图, 整体功能很清晰, 但每个组件都没有体现出有任何安全性的保证.
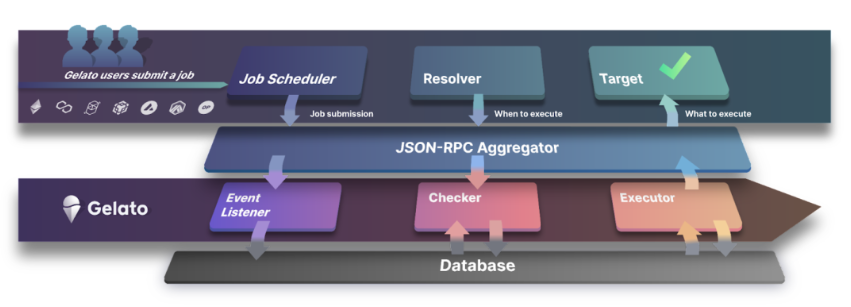
以两个典型的 Keeper Network 为例, 它们的安全性机制是:
- Gelato: 目前的 Keeper 服务执行节点不是 Permissionless 的, 而是在白名单上的节点才可以参与. Gelato 预计在未来去中心化之后, 通过 Stake and Slash 机制和 DAO 来保证网络安全性. 但是去通过 DAO 来惩罚一个非法节点需要一周, 这样缓慢的决策对一个需要高频运转的服务来说, 我认为是完全没法接受的.
- Keep3r Network: 和 Gelato 类似, 也是 Watcher 监督, 发现非法行为则举报给 DAO. 但机制阐述得更加详细, 虽然依旧是很差的机制, 需要大量的人工交流和漫长的步骤.
就像我们刚才提到的 Indexing 协议一样, Keeper 也完全可以通过 zk 化来解决安全性的问题, 同时甚至可以 Gelato 的 off-chain resolver 也是用 GraphQL 定义的一个 subgraph, 但和 The Graph 没有安全性保证. 这两个问题就可以被一起解决了.
这样一个带可信 off-chain resolver 的 zk 化 Keeper 可以解锁无数新的应用场景:
- 复杂策略的交易机器人
- 跨 Cluster/跨链/跨区块/跨 DEX 的套利/做市机器人
- Programmable Liquidity (调整区间, JIT, 复投, Rebalance)
Crypto-Native ZK Infra
在 zkEVM 和通用 zkVM 的最底层 infra 成熟的过程中, 我们已经可以尝试去基于和使用它们来建立开发者可以直接使用的 infra, 包括我们构想中的这些 zk 化中间件.
ZK 作为一个典型方案, 是像 AMM 一样的创新驱动重要因素. ZK 和 AMM 分别解锁了比 Optimistic 和 Order Book 机制更自动化和更可信的应用运转, 让安全性在链上完全透明公开可验证, 同时也分别解锁了证明外包和 Swap 聚合器的额外赛道, 解锁了无数新的应用.
除了扩容/跨链轻节点/隐私/机器学习以外, ZK 作为完全适合区块链场景 (网络全体做验证, 极其自动化, 甚至比网络共识更强的安全性) 的密码学方案, 在 Indexing 协议与 Keeper 网络这些中间件赛道中也大有可为. 我们也将持续关注 ZK 在更多领域中的应用.
(声明:请读者严格遵守所在地法律法规,本文不代表任何投资建议)
